Humans of Paris 1900: Difference between revisions
| Line 241: | Line 241: | ||
| Create FaceMap using D3 | | Create FaceMap using D3 | ||
|- | |- | ||
| colspan=" | | colspan="2" align="center" | '''''Week 11''''' | ||
|- | |- | ||
| rowspan="3" | ''25.11'' | | rowspan="3" | ''25.11'' | ||
| Integrate all functionalities | | Integrate all functionalities | ||
| | | rowspan="2" align="center" | ✓ | ||
|- | |- | ||
| Finalize project website | | Finalize project website | ||
|- | |- | ||
| colspan="3" align="center" | '''''Week 12''''' | | colspan="3" align="center" | '''''Week 12''''' | ||
Revision as of 12:45, 12 December 2019
Motivation
We take inspiration from the famous Instagram page, Humans of New York, which features pictures and stories of people living in current day New York. In similar fashion, our project, Humans of Paris, has the aim to be a platform to connect us to the people of 19th century Paris. Photography was still in its early stages when Nadar took up the craft in his atelier in Paris. Through the thousands of pictures taken by him and his son we can get a glimpse of who lived at the time. We explore the use of deep learning models to cluster similar faces to get an alternative, innovative view of the collection and allowing for serendipitous discovery of patterns and people. There is a story behind every person, and our interface highlights this by association people’s story with their picture.
Historical Background
The collection at the heart of our project is comprised of 23000 photographs (positives) and caricatures by Atelier Nadar. We focus on individual portraits of people for our interface.
The portrait studio Atelier Nadar was founded by Nadar, otherwise known by his birth name Felix Tournachon (1820-1910). Nadar first established himself as a known caricaturist after working in journalism. Then, having been introduced to photography by his Brother, Adrien, he soon realized the potential of this new arform. With the support of a banker friend he went on to create the Studio in Paris in 1854. (https://www.metmuseum.org/toah/hd/nadr/hd_nadr.htm)
Photography had started to become a viable business as new collioduim-on-glass negatives, invented in 1851, allowed for the creation of copies from one negative while being cheaper than previous methods due to the use of glass all while having short exposure times. (https://www.metmuseum.org/toah/hd/nadr/hd_nadr.htm)
The studio was frequented by anyone in the public eye, be it politicians, famous artists and writers of the time. Famous individuals of the time, that are still of large cultural importance today, captured in the photos include Liszt, Victor Hugo and Baudelaire. His minimalistic, no-frills style as well as lack of editing allows the photos highlight the expressions, and as such the personalities of his subjects.
Nadar himself believed that what set him apart from other photographers was his feel for light and how he connected to the subjects of his photographs.s His talent in engaging with people was especially important as in the mid 19th century the camera was a bulky box under which the photographer would disappear. (https://www.theguardian.com/books/2015/dec/23/books-felix-nadar-france-photography-flight)
Later, starting 1860, as Nadar himself moves on the other endeavors, his son, Paul, took over the studio. Paul moved the studio into a more commercial direction, in part due to the increasing competition. A different style of photography started to emerge from the studio, such as theater photography as well as miniature portrait photography.
The collection held by the french state was acquired in 1949, since 1965 the positives of the Photos are stored with the BnF, while the negatives are held at Fort de Saint-Cyr.
Implementation
Website Description
In more concrete terms, our project involves four core interfaces motivated by the above.
- A home page highlighting the most known individuals
- A page (FaceMap) that highlight similarities in differences in the faces of the people in the dataset.
- A page to find your 19th century doppelganger, for fun and to gather interest in people the user my otherwise would never have known existed.
- A way to search using tags, to allow users to find individuals of interest.
To each person in the pictures we associate background information crawled from wikipedia.
Methods & Evaluation
Getting & Processing Metadata
As a first approach, we use the library provided by Raphael to get a list of all the photos in the collection of the foundation Nadar on Gallica. Nadar's collection contains a variety of genres: portraits, comics, caricatures, paysage, sculptures, etc. In order to stick to our emphasis on ‘people of 19th century Paris’, we filtered out photographs that are not directly relevant to people of that time.
- Getting individual portraits
We used metadata of Gallica collection to filter irrelevant photographs. Among a number of attribute objects in the metadata, we concentrated on ‘dc:subject’ attribute. This field contains a list that has detailed information about the photograph and the entity in that photo: [Names of individuals],(year of birth - year of death) -- [genre of the photograph]. For each row, We ignored subjects that do not have the substring “-- Portraits” and returned the new list of subjects. This way, we can discard the landscape, comics, caricatures, and sculptures. After filtering only ‘Portraits’, we had column of list that varied in length: that is, the number of people featured in photographs differed. Since our intention is to connect ourselves to people of 19th century Paris by presenting story of each Parisien-ne in the photograph, we filtered out the photographs that features more than one person. In order to filter and get insights of people who work in the same field or had the same role we created the concept of tags that helps us to access and query groups of people.
- First attempt
Gallica ‘dc:subject’ metadata had very brief information on each person - only name, year of birth, and year of death, which are not enough information to sort categorize each person. On the other hand, there is ‘dc:title’ metadata that gives title of each photograph, but they were variance in texts. Moreover, for some photographs, especially ‘Portrait du theatre’, the descriptions were on fictional characters which some performers had represented, not on the performers. As a result, we had to find another dataset to finish this task.
- Second attempt
Data.bnf.fr is the project driven by BnF in order to make the data produced by the BnF more visible on the Web, and federate them within and outside the catalogues. Since Gallica is one of the BnF projects, it is reasonable to assume that a person who has their name in Gallica metadata will have some document or page in data.bnf.fr semantic web. In order to get corresponding pages, we queried metadata though python SPARQL API Data.bnf XML schema has three name attributes: foaf:name, foaf:givenName, foaf:famliyName. We checked how names in <dc:subject> is arranged, compare the arrangement with some names in Data.bnf, rearranged names accordingly, then queried them.
Sometimes query result contained different entities that have the same name. For this case, we exploited the fact that we are handling 19th century data, taken by one author, Nadar. Among the namesakes, we chose the one whose living period overlaps the most with that of Nadar.
Creating Tags out of metadata
Table from data.bnf html page contains a variety of useful information: name, nationality, language, gender, short description, etc. We used description and nationality to create tags. Our idea of extracting tag from descriptions is using most frequent nouns that appears across different people, except stopwords The problem here is that, some important keywords and entities are broken down under wordcount. For example, “Legion d’honneur”, is split into “legion” and “d’honneur” and the original meaning is lost. This is handled by manual jobs. First, we checked the wordcount without stopwords, and got the frequent words that are not profession-related nouns. We checked the notes that contain those words and examined if they are part of important (and frequent) phrases. For the phrases that are found, we concatenated them into one word, so that they can be used as tag. After this step, we fetched 300 major keywords, some being feminin or plural conjugation of another. Cleaning those semantic duplicates were done manually. For future improvement, this job can be done by using proper french NLP library. Once creating list of all possible tags is done, we can assign tags for each picture by having intersection between list of all tags and list of words in each description. Finally, nationality is added in the list of tags.
Using Wikipedia as criteria of importance
Data.bnf contains useful information on each person, but it is hard to infer their historic influence only by looking at the table. So we used wikipedia as a criteria that define people’s ‘importance’ - more images they have in their page, more important. We used Wikipedia API library that is available in pypy (https://pypi.org/project/wikipedia/) The library instance contains Wikipedia page, number of images and reference links they have. Moreover, it has auto-suggestion, so the query string does not have to be an exact match with the article we are looking for. Sometimes auto-suggestion fails. To handle these cases, we verified if the content of Wikipedia page contains the name and the birth/death year of the person.The wiki content that does not have enough match were considered false positives and neglected. The number of images in each Wikipedia page defines ‘weight’ of the person. We got this for English and French Wikipedia in order to represent the importance outside francophone culture as well. The final weight (or importance) is the average between two, so the ones that have Wikipedia pages for both languages are boosted in importance.
Evaluation'
| Metadata | Accuracy (%) |
|---|---|
| Data.bnf.fr page | 94 |
| English Wikipedia | 100 |
| French Wikipedia | 98 |
Image processing and cropping
To get nicer visuals we decided to crop the background on which the photograph is placed. Cropping the background is done based on edge detection. We base our code off of (https://github.com/polm/ndl-crop) but make modifications to adapt it to use on sepia photography on blue backgrounds. This involves adding an additional preprocessing step that sets the blue background to white. We determine the background using the RGB values. It uses image processing techniques provided by OpenCV to find the contours in the images, from which we infer boundaries. Setting the blue background to white gives us better contour detection. Using heuristics about the size of the photo against the background we then choose the most appropriate boundary. See figure x to see an example of the process.
Cropping the face is done using the facial rectangle returned by the py-agender api (see below) and MTCNN. MTCNN (https://github.com/ipazc/mtcnn) is an other python library implementing a Deep Neural Network as proposed by FaceNet (also used to find the facial vectors, see openface). Py-agender is much quicker, so we use it for the initial cropping.
Evaluation
To check how well the background is cropped, we randomly sampled 100 images and check for the cropping. 91% of images are correctly cropped. The incorrectly cropped images contain some border. None of them are overcropped. We might be able to do better by tuning the assumptions we make to choose the most appropriate boundary, as we are currently missing very large pictures and very small ones. But for the current stage of the project we find the accuracy to be sufficient.
Looking at the face cropping done with py-agender, we find a total of 52 incorrectly cropped images. We also find 71 images where no face could be found, despite there being one in the image. We find this number by looking through all 1874 cropped images. We rectify that badly cropped images using the MTCNN library, which correctly identifies that cropped images that do not contain a face and correctly crops those images given the original image. In the end we get 5 incorrectly cropped portraits. They are all from very washed out and damaged photos. We replace those images with manually cropped faces.
Age and Gender
Given the data at hand, we have to use a method to guess the age and gender of a person based on a photo or their name, in the case of gender. We later find the data.Bnf has ground truth labels for many individuals in the database. We later use this for the evaluation. Note that we use the ground truth labels in our final product. We now describe the methods used under the assumption that no such labels were available. However, a quick survey of available methods to detect gender from names shows that no database adapted to the task of classifying 19th century french names exists. Not having the means to create such a database from scratch, we focus on the photo and faces in them. Detecting age and gender from photos has long been a topic of Deep Learning research. Many pretrained state of the art models trained on modern data exist. People presumably have not changed much in 100 years, so we can expect methods to work well.
We use the python library py-agender which implements a state of the art model proposed by Rasmus Rothe et al. and the implementation on https://github.com/yu4u/age-gender-estimation. It iis trained on the IMBD-Wiki dataset https://github.com/imdeepmind/processed-imdb-wiki-dataset.
The library endpoint returns a list of dictionary objects containing the facial rectangle, gender as a value between [0, 1], 1 indivating male, 0 indicating female and age, as a floating point number. We get estimates for all individuals in the dataset, based on one image. We first try for one random image per individual, and if the model can not detect a face, we try another image, until we get a result or no more images are left.
Evalutation The underlying model itself has limitations. As can be seen in figure https://raw.githubusercontent.com/wiki/yu4u/age-gender-estimation/images/loss.png validation loss for both age and gender are still high, despite being the state of the art.
{kind=link}
When it comes to the models application to our data, we create a histogram of all the estimates we get. The histogram for gender is strongly skewed towards male values. We know that we have many women in the photos. Clearly, the model is not working well. As the clustering algorithm we used separated women and men in rather neat clusters, we use this to estimate how bad the misclassification is. Finally, given the true labels we find the following rate:
| True Male | True Female | |
|---|---|---|
| Labeled Male | 1393 | 114 |
| Labeled Female | 237 | 130 |
Doing a qualitative analysis of the 100 images, we formulate the following hypothesis why the gender estimation model creates so many errors. While people’s faces have not changed, these days women tend to have long flowing hair and wear more visible makeup. This is not the case in our dataset where women appear to mostly have updos and wear barely visible makeup. An additional issue might be the angle at which people posed.
The age histogram follows a gaussian like distribution centered around 40. It is much harder to estimate whether this is an accurate assessment. The metadata does not give us any information on when the photo was taken. For this reason we just use random sampling to get a subsample of 95 images on which we do a qualitative evaluation. We annotate the samples by the age, but only giving the decade. Even for humans guessing the age is difficult. We are only interested in an estimate - decades are enough. For 72 out of 95 we get the decade correct. The age estimation algorithm works reasonably well. For the ones that we do miss, the difference between the exact age estimation on the estimated decade is less than a full decade.
Getting the face vector for facemap and doppelganger search
To represent a complex object such as the image of a face in two dimensional space and examine similarities between faces we need to convert it into a vector space. This can also be done using a Deep Learning model. We use the openface, an implementation based on the CVPR 2015 paper FaceNet: A Unified Embedding for Face Recognition and Clustering by Florian Schroff, Dmitry Kalenichenko, and James Philbin at Google. The general workflow for facial detection is summarized in figure https://raw.githubusercontent.com/cmusatyalab/openface/master/images/summary.jpg. As can be seen the method first finds a bounding box and important facial landmarks, which are then used to normalize and crop the photo. This cropped photo is then fed to the neural network, which returns points lying on a 128D hypersphere. Issues can arise at each step of this process. The special property of the resulting vector is that euclidean distance in the feature space represents closeness in facial features.
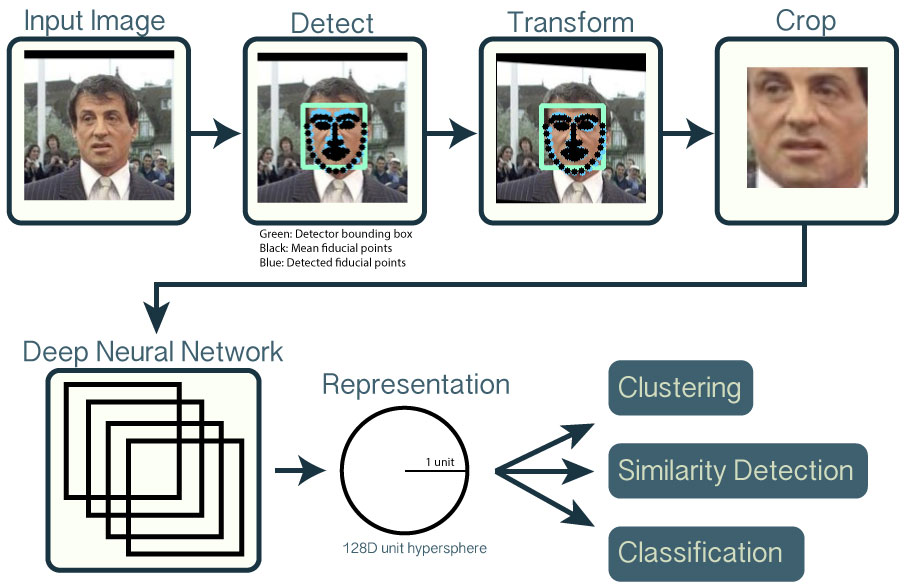{kind=link}
To find a person's doppelganger we can therefore use cosine similarity between the vectors of the people in our dataset and the vector of the person who uploads their image.
To display the facemap we need 2D vectors. Going from a higher dimensional space (in our case 128) to a lower dimensional space - in our case 2 - requires the use of dimensionality reduction algorithm to project the higher space vector into a lower dimensional space. We tried a total of two dimensionality reduction algorithms, the linear method PCA and the non-linear method T-SNE.
Evaluation
- Creation of face vector:
To estimate the quality of the resulting vector we again have the accuracy of the underlying method, and how it applies to our case. The deep learning method used to generate the vector is trained on a face classification task. On this task the model has accuracy of 0.9292 ± 0.0134 and AUC (area under curve) of 0.973. Human annotators can achieve AUC of .995 on the task. The papers also discusses the application of the face vectors to clustering. They note that the method is invariant to occlusion, lighting, pose and even age.
On our task, we check whether the face is correctly detected and how well the resulting vector works for the tasks at hand - clustering and finding doppelgängers. Due to the style of photography, we can not produce a face vector as they show only their profile in the images. The models we use are not adapted to such a strong variation from frontal pictures. In total, we have 71 people for which we can not find vectors. For the remaining ones we find that the model detecting the faces works well - we can not find incorrectly cropped images.
Frontend
Use adobe xd to do initial prototype to explore how to design frontend and then use bootstrap templates to match our prototypes. We us D3.js to make the facemap interactive.
D3 (Data-Driven Documents) is the most flexible javascript library to produce interactive data visualizations. Even though it has a lot of built-in functions, it also gives total control to the programmer customize its own visualizations. In order to adapt D3 to have a better zooming of the images we used https://github.com/karpathy/tsnejs which uses perperxity to calculate the distance between images based on the predefined clusters (see discussion of clustering).
Backend
To render images and text to a web interface we use Django 2.2.7 which is a powerful web framework written in python. Combined with scripts written Javascript, they give the frontend behavior that we see and interact on the site. Django also contains its own ORM (object-relational mapping) layer which turns easy to store data, update and query it to be handled on the interface. The data model used to deal with diverses granularities and sources is given below:
Underneath we are using Sqlite3 to store our data however due to the ORM properly that turn the storage option agnostic with respect to the code and framework implementation.
Unfortunately openface is just available in python2.7 which will be deprecated in January 2020 and our project was written in python3. In order to run both versions smoothly when a new image is uploaded we decided to spin openface separately as another service that receives a post request with a new image and returns the encoded vector to the original website. The openface project was forked here and on top of that we implemented a Flask application who is ready to receive post request at the endpoint \get_vector and returns json response which will be consumed by our application and find the doppelganger.
Project execution plan
Milestones
| Timeframe | Task | Completion |
|---|---|---|
| Week 4 | ||
| 07.11 | Understanding Gallica Query Gallica API | ✓ |
| Query Gallica API | ||
| Week 5 | ||
| 14.10 | Start preprocessing images | ✓ |
| Choose suitable Wikipedia API | ||
| Week 6 | ||
| 21.10 | Choose face recognition library | ✓ |
| Get facial vectors | ||
| Try database design with Docker & Flask | ||
| Week 7 | ||
| 28.10 | Remove irrelevant backgrounds of images | ✓ |
| Extract age and gender from images | ||
| Design data model | ||
| Extract tags, names, birth and death years out of metadata | ||
| Week 8 | ||
| 04.11 | Set up database environment | ✓ |
| Set up mockup user-interface | ||
| Prepare midterm presentation | ||
| Week 9 | ||
| 11.11 | Get tags, names, birth and death years in ready-to-use format | ✓ |
| Handle Wikipedia false positives | ||
| Integrate face recognition functionalities into database | ||
| Week 10 | ||
| 18.11 | Create draft of the website (frontend) | ✓ |
| Create FaceMap using D3 | ||
| Week 11 | ||
| 25.11 | Integrate all functionalities | ✓ |
| Finalize project website | ||
| Week 12 | ||
| 02.12 | Write Project report | |