WikiBio: Difference between revisions
Jump to navigation
Jump to search
Michal.bien (talk | contribs) |
|||
| Line 47: | Line 47: | ||
== Evaluation == | == Evaluation == | ||
=== | === Objective (automatic) === | ||
=== | === Subjective (survey) === | ||
Revision as of 13:52, 19 November 2020
Motivation
The motivation for our project was to explore the possibilities of natural-language generation in the context of biography generation. It is easy to get structural data from the Wikidata pages, but not all the Wikidata pages have a corresponding Wikipedia page. This project will showcase how we can use the structural data from the Wikidata pages to generate realistic biographies in the Wikipedia pages format.
Project plan
| Week | Goals | Result |
|---|---|---|
| 1 | Exploring data souces | Selected Wikipedia + Wikidata |
| 2 | Matching textual and structural data | Wikipedia articles matched with wikidata |
| 3 | First trained model prototype | GPT-2 was trained on english data |
| 4 | Acknowledge major modelling problems | GPT-2 was trained in Italian, issues with Wikipedia pages completion and Italian model performances |
| 5 | Code clean up, midterm preparation | Improved sparql request |
| 6 | Try with XLNet model, more input data, evaluation methods | Worse results with XLNet (even with more input data), Subjective quality assessement |
| 7 | Start evaluation surveys and automatic evaluation | ... |
| 8 | Productionalization, finish evaluation | ... |
| 9 | Productionalization, evaluation analyse | ... |
| 10 | Final Presentation | ... |
Data sources
In this project, we make use of two different data sources:
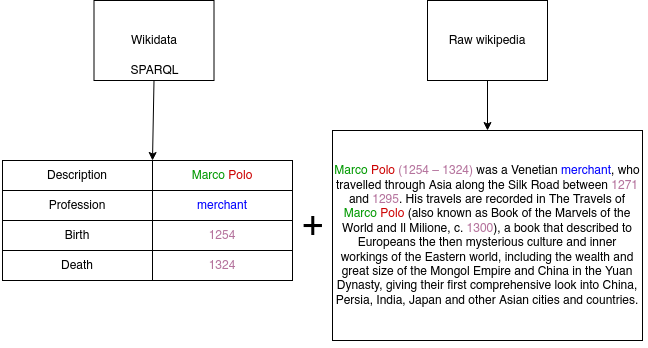
- Wikidata is used to gather the structured information about the people who lived in the Republic of Venice. Multiple information are extracted from their wikidata entries, such as: birth and death times, professions and family names. To gather this data from wikidata, a customizable SPARQL query is used on the official wikidata SPARQL API
- Wikipedia is used to match the wikidata entries with the unstructured text of the article about that person. The "Wikipedia" package for python is used to find the matching pairs and then to extract the Wikipedia articles matching the entries.
The output of the above data sources is prepared jointly in the following manner:
- All the structured entries are transformed to text, by putting the custom control token in front of them and then concatenating them together

The schema of data acquisition step
