WikiBio: Difference between revisions
Michal.bien (talk | contribs) |
|||
| (75 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
Our first motivation for the project was to explore the possibilities of natural-language generation. Having at our disposal a big and accessible database like is Wikipedia, we wanted to generate a Wikipedia page that is written as human-like as possible. | |||
Our first challenge was to define our training dataset. To do this at first we wanted to use English Wikipedia pages of people who lived in Venice, but we soon realized that the criteria wasn't precise enough and included a large period of time. Therefore we restrained it to the people who where citizens of the Venice Republic. This criteria is precise enough to be registered in the Wikipedia information and would fit the image of a person living during the Middle-Age in Venice (Since the Venice Republic existed from 697 AD until 1797 AD). | |||
In order to select the training data, we used the structural data of the Wikidata dataset that is linked to the corresponding Wikipedia page. During the data retrieval process, we noticed that from the 3 thousands entries on the Wikidata, only half of them had a corresponding English Wikipedia page. They are multiple reasons for this but it is mainly due to the fact that they are only available from a Wikipedia in an other language (mostly in Italian) and also the fact that the two platforms (Wikipedia and Wikidata) are complementary and publishing content on one platform will not directly create any content on the other. | |||
For that reason we decided that the final goal of our project would be to populate a Wiki website with English biographies generated from the structured data of the Wikidata entries that are missing an English Wikipedia page. We will also explore the achieved results by evaluating the generated biographies using both automatic metrics and human opinion scores. | |||
The final result of our project is easiest explorable on the website https://wikibio.mbien.pl | |||
== Project plan == | == Project plan == | ||
| Line 6: | Line 13: | ||
{| class="wikitable" | {| class="wikitable" | ||
|- | |- | ||
! Week !! Goals!! Result | ! Week !! Dates !! Goals!! Result | ||
|- | |- | ||
| 1 || Exploring data souces|| Selected Wikipedia + Wikidata | | 1 || 8.10-15.10 || Exploring data souces|| Selected Wikipedia + Wikidata | ||
|- | |- | ||
| 2 || Matching textual and structural data|| Wikipedia articles matched with wikidata | | 2 || 15.10-22.10 || Matching textual and structural data|| Wikipedia articles matched with wikidata | ||
|- | |- | ||
| 3 || First trained model prototype|| GPT-2 was trained on english data | | 3 || 22.10-29.10 || First trained model prototype|| GPT-2 was trained on english data | ||
|- | |- | ||
| 4 || Acknowledge major modelling problems|| GPT-2 was trained in Italian, issues with Wikipedia pages completion and Italian model performances | | 4 || 29.10-5.11 || Acknowledge major modelling problems|| GPT-2 was trained in Italian, issues with Wikipedia pages completion and Italian model performances | ||
|- | |- | ||
| 5 || Code clean up, midterm preparation || Improved sparql request | | 5 || 5.11-12.11 || Code clean up, midterm preparation || Improved sparql request | ||
|- | |- | ||
| 6 || Try with XLNet model, more input data, explore evaluation methods|| Worse results with XLNet (even with more input data), Subjective quality assessment and Bleu/Gleu methods | | 6 || 12.11-19.11 || Try with XLNet model, more input data, explore evaluation methods|| Worse results with XLNet (even with more input data), Subjective quality assessment and Bleu/Gleu methods | ||
|- | |- | ||
| 7 || Start evaluation surveys and automatic evaluation, improve GPT-2 input data|| | | 7 || 19.11-26.11 || Start evaluation surveys and automatic evaluation, improve GPT-2 input data|| Survey started, introduced full-article generation with sections | ||
|- | |- | ||
| 8 || Productionalization, finish evaluation|| .. | | 8 || 26.11-3.12 || Productionalization, finish evaluation|| Created wikibio.mbien.pl to present our results and started working on API for page uploads | ||
|- | |- | ||
| 9 || Productionalization, evaluation | | 9 || 3.12-10.12 || Productionalization, evaluation analysis || Finished the wikipage, uploaded code and prepared the presentation slides | ||
|- | |- | ||
| 10 || Final Presentation || | | 10 || 10.12-16.12 || Final Presentation || Who knows? | ||
|} | |} | ||
== Data sources == | == Data sources == | ||
[[File:Marcopolo3-data.png|thumb|The schema of data acquisition step]] | |||
In this project, we made use of two different data sources: Wikidata and Wikipedia | |||
=== Wikidata === | |||
Wikidata was used to gather the structured information about the people who lived in the Republic of Venice. To gather this data from wikidata, a customizable SPARQL query is used on the official wikidata SPARQL API. | |||
Only two strict constraints were set for data filtering: | |||
* Instance of (wdt:P31), human (wd:Q5) | |||
* Citizenship (wdt:P27), Republic of Venice (wd:Q4948) | |||
Optionally, following data was also gathered - we used it for generation whenever they existed in the data | |||
* | * ID of the object in the wikidata | ||
* itemLabel (wikibase:label) - generally either equal to the person's full name, or the wikidata ID | |||
* itemDescription (schema:description) - short, generally two-word, description of the person | |||
* birth year (wdt:P569) | |||
* death year (wdt:P570) | |||
* profession (wdt:P106) | |||
* last name (wdt:P734) | |||
* first name (wdt:P735) | |||
* link to picture in commons (wdt:P18) | |||
=== Wikipedia === | |||
Wikipedia was used to match the wikidata entries with the unstructured text of the article about that person. The "Wikipedia" package for python was used to find the matching pairs and then to extract the Wikipedia articles matching the entries. | |||
== Generation methods == | == Generation methods == | ||
The output of the above data sources is prepared jointly in the following manner: | |||
* All the structured entries are transformed to text, by putting the custom control token in front of them and then concatenating them together | |||
* The resulting text is the training sample for the model | |||
We considered two language model architectures: XLNet and GPT-2. We used Huggingface Transformers library backed with PyTorch in both cases, as the SOTA environment for training and sharing the Transformers models. The comparison of the models and reason of selection of GPT-2 is described below: | |||
=== XLNet === | |||
XLNet is a late-2019 bi-directional language model, mostly used for tasks like sentiment analysis, classification and word correction. However, it was interesting for us due to its possibility to train on and generate text samples of virtually infinite length. | |||
Pros: | |||
* variable text length | |||
* modern architecture | |||
Cons: | |||
* bi-directionality is not of much use here and takes more memory | |||
* considerably lower performance on text generation tasks than GPT-2 | |||
Finally, our tests has shown that we should not consider XLNet for our biography generation effort, for a number of reasons: | |||
* there is no text sample length limit, but the GPU RAM is not, which makes the limitation to ~1500 tokens required anyway | |||
* the model performs poorly with short inputs | |||
* the text is gramatically correct but the coherence with semistructured data is very bad, supposedly due to bi-directional nature of the model | |||
=== GPT-2 === | |||
GPT-2 is an early-2019 Causal (left-to-right) Language Model. It it widely used for language modeling for text generation, and as such it was perceived as the best shot to get the decent language modeling performance. | |||
Pros: | |||
* modern architecture | |||
* left-to-right: memory-efficient | |||
* widely used for text generation | |||
Cons: | |||
* fixed 1024 tokens context frame | |||
The model performed well to understand the semi-structured input based on the underlying wikidata. It allowed generating short, but consistent biographies. | |||
=== Example generation output === | |||
* Input: <|start|> Marco Polo <|description|> Painter <|professions|> Painter, Writer <|birth|> 1720 <|death|> 1793 <|summary|> | |||
* Output: Marco Polo (1720 – 1793) was a German painter of a distinguished life of high quality. In 1740 he was the first to paint in an Italian Renaissance style. He served as the painter of Giovanni Venez in Venice; his brother was Giovanni Magnan and daughter was a painter of his own time, Marco Polo. During his career he collaborated with the great Venetian painter Giovanni Battista Gugliati in the work for the Porte della Prudina, which was published in 1714. After his death, he would leave his paintings at Venice for the Palace of Santa Martina. | |||
=== Generation hyperparameters tuning === | |||
In this section, we elaborate on the possible generation parameters, and their effect on the final model output. The comparison is based on our understanding of these metrics, proposed in the document "How to generate" by Huggingface: https://huggingface.co/blog/how-to-generate | |||
* Repetition penalisation: | |||
The generation pipeline implements two methods to control the repetitions in the generated text. First, repetition_penalty, is a penalty metrics which decreases the score of the repeated token with each consecutive occurence. Then, no_repeat_ngram_size bans the use of the ngrams more than once by setting their probability to zero if they already exist in the text. In the evaluation section, we show how use of these two methods influence the opinion score on the model generation. | |||
* Beam Search: | |||
This greedy generation method is famous for giving very good, but very boring text results. We used it extensively for the generation of biographies for human evaluation. However, as the beam search practically eliminates the randomness of the results given its greedy approach, this method was not used for the wiki biographies generation. | |||
* Top-K, top-P sampling: | |||
Method which selects random token out of K tokens of highest probability, but only if their probability is over the P threshold. While the results are not as good as the ones of beam search, the resulting articles are much more interesting and, thanks to the randomness, can be generated many times with different results. This method was used to generate wikibio in the final generation pipeline. | |||
== Productionalization == | |||
[[File:Biographypipeline.png|thumb|The flowchart of automatic biography generation pipeline]] | |||
=== Platform === | |||
To serve the generated biographies, we created the MediaWiki website: https://wikibio.mbien.pl/ | |||
The platform was based on the private server, running the docker-compose stack. The used containers were: | |||
* mediawiki 1.35 from https://hub.docker.com/_/mediawiki | |||
* mariadb 10.5 from https://hub.docker.com/_/mariadb | |||
The server was also running traefik 1.7 as an ingress gateway and TLS terminator. | |||
Functionalities such as Infobox:Person, required significant manual modifications to the vanilla MediaWiki installation. To enable this functionality, it was required to perform all the operations described in the following tutorial: https://www.mediawiki.org/wiki/Manual:Importing_Wikipedia_infoboxes_tutorial. Finally, the logos and favicons were replaced with the coat of arms of Republic of Venice, to give the platform more pleasant look. | |||
=== Automatic generation pipeline === | |||
The final generation pipeline was a complex, multi-phase operation. While the survey-based evaluation of our model was meant to show the overall performance, here we wanted to get only the well-conditioned biographies, ready to be served to the users. The overall pipeline is visible in the following diagram, with details explained in the further subsections | |||
==== Post-processing wikidata ==== | |||
In general, itemLabel extracted from the wikidata was meant to contain the person full name. However, it was not always the case. Some labels contained the wikidata ID of the entry. These samples were found, and, whenever possible, their labels were replaced with the first and last name acquired via the data optional fields. If those fields were not existing either, the sample was dropped, having not enough information to start the generation. | |||
==== Generation with structural accuracy score ==== | |||
After the data was ready, we used our fine-tuned GPT2-medium model to generate 20 biographies. The generation sampling setup was top_p=0.97, top_k=10. Each of the generated biographies was then checked for validity: | |||
* Whether it was complete - if it has less than 1024 tokens, or if the last token is the pad or end token. | |||
* Whether there were no duplicate sections | |||
* Whether there were no generated control tokens in the textual part of the biography | |||
Then, the structural accuracy scores were calculated for each of the remaining biographies (see the metric details in evaluation section). If the best biography reached over 0.95 structural accuracy, the biography was accepted. Otherwise, the threshold was decreased by 0.05, and the generation procedure was repeated. | |||
==== Procedural enrichment of the output ==== | |||
The output of the generation was plain text divided into sections. It was important to increase the article plausibility using several post-processing methods: | |||
* First, the text was processed using SpaCy NER model en_core_web_lg. The entities related to locations (GPE) and to the universities (ORG with "university" substring) were manually tested to perform well without further NER training. Each detected entity was replaced with link to the wikipedia page, without checking the actual existence of such a page. The links were intentionally made to look like the internal links to the existing pages on WikiBio. This made the articles more convincing, and in most cases, the links were actually working. | |||
* Finally, the infobox was created using the imported Wikipedia "Template:Infobox person". Besides all the information acquired from the wikidata and used for generation, the biography was also enriched with the picture, whenever it was present in the original wikidata. Thanks to the MediaWiki's InstantCommons feature, it was not required to gather the images: they were forwarded automatically from Wikimedia Commons based on the provided image name. | |||
==== Wikipedia page upload using Pywikibot ==== | |||
The final biography text, consisting of plain-text with NER-based links and infobox, was then saved as a WikiBio page. pyWikibot library was used to build a MediaWiki bot and the special bot account credentials were generated for this occasion. The pipeline was running for about 17 hours in total, on Google Colab Tesla V100, resulting in 1389 generated biographies. | |||
== Evaluation == | == Evaluation == | ||
[[File:Evaluation-bio.png|thumb|Evaluation schema]] | |||
=== Objective (automatic) === | |||
We used three different approaches for automatic evaluation. The translation metrics such as BLEU or GLEU are SOTA for generic text generation tasks, therefore there was a possibility that they could work in this case as well. Then, we implemented a naive check method, named structural accuracy, which was used to assess the biography quality in the final generation task. Finally, we worked on the new metric, codenamed (Top-TIKPIT Neighbours), which was meant to be tailored for the specifics of our task and better explain the differences between the original and generated data in a visual way. | |||
==== Translation metrics ==== | |||
We wanted to use translation metrics (BLEU and GLEU) in the manner typical for this kind of tasks. That is, we generated multiple biographies, which we put as a reference to test the hypothesis - real biography. This way, the real biography should score higher given the better reference biographies, which implies the better generation in the indirect manner. | |||
Unfortunately, the metric didn't provide any conclusive results. The variance of the scores was very high (from 0.01 to 0.32), and the metric have sometimes scored better on the samples, which we perceived as much worse. It became clear that in encyclopedic articles, the linguistic smoothness and use of specific words is not as important as the fact coherence and ideas abstract from the linguistic perspective, such as time spans or event precedence. We decided to continue our efforts with other metrics. | |||
==== Structural accuracy ==== | |||
The structural accuracy is a naive, but very efficient method we used to evaluate the coherence between the provided data and generated biography. The method was successful enough to be incorporated into the production pipeline. This is how it works, in three steps: | |||
* The tokens are removed from input structure: | |||
"<|start|> Marco Polo <|description|> Painter <|professions|> Painter, Writer <|birth|> 1720 <|death|> 1793 <|summary|>" -> "Marco Polo Painter Painer, Writer 1720 1793" | |||
* The remaining structure is lowercased and split into tokens. Only alphanumeric characters are kept, stopwords are removed using NLTK english stopwords list: | |||
"Marco Polo Painter Painter, Writer 1720 1793" -> ["marco", "polo", "painter", "writer", "1720", "1793"] | |||
* The generated text is evaluated for presence of the listed words. The percentage of the words present in the text become the score. | |||
For example generation output from section "Generation methods": The name and years are correct, however there is no mention of "writer" - the score is 0.83. This example shows clearly, how this rough approximation of the biography "validity" can be a useful tool - it correctly scored the biography of painter-writer lower, because the generated text was only about the painter. | |||
==== KNN over top TF-IDF Keywords for Profession in Time (Top-TIKPIT) matrix (Top-TIKPIT Neighbours) ==== | |||
[[File:Top-tikpit-small.png|thumb|Top-TIKPIT visualization for politicians in time (left to right) for real and generated data (up vs bottom)]] | |||
The method codenamed Top-TIKPIT was our final, last-minute idea for reasonable and explainable model evaluation. The same algorithm is used separately on original and generated data, and then the results are compared: | |||
* Split the dataset into parts, based of the person profession | |||
* For every part, split it once more, based on the century the person lived in ((birth+death)/2 if both dates are available) | |||
* Join all the text in the smallest parts. Flatten the array so that the number of strings is professions_num*centuries_num | |||
* Treat every text as a doc for TF-IDF vectorizer, fit and transform the data | |||
* For every document, extract top TF-IDF tokens | |||
This Top-TIKPIT matrix can be easily visualized, preferably with X being the time and Y being the occupation. Note that the axes are discrete. The time span and number of top TF-IDF tokens can be customized. The performance of the model can be assesed based on how well it manages to reproduce important topics for the class of citizen of the given century. | |||
The metric can be assessed either visually, or using multilabel accuracy metric. There is also an area for further work, where we can try to make the axes continuous and assess the biography quality by checking the Top-TIKPIT for the K-Nearest-Neighbors | |||
=== Subjective (survey) === | === Subjective (survey) === | ||
With objective metrics we were more or less able to evaluate the validity and the correctness of the generated biographie, but we had a hard time to define exactly what makes a good biography and to find a metric that would assess the quality of the generation. Therefore, we conducted a qualitative assessment survey. We generated a biography from six random entries on the Wikidata that don't have an English Wikipedia page for each different models that we wanted to test, five models in total. Comparing the 5 biographies generated, the experts would first give a score from 1 to 10 to each biography and then rank them in order of quality. This assessment compares mainly the repetition penalisation parameters. | |||
The result of the assessment is shown in the following figures. The two featured models (V1 and V2) are quite similar, beside that V2 as more more parameters. Each setting is described with his name, for example "V1_b3_r3_n0". | |||
*v1/v2 describes wich model was used. | |||
*p? describes the top-P sampling parameter. If it is p0 there top p sampling wasn't used. | |||
*b? describes the number of beams for beam search.Top_p and num_beam are incompatible. | |||
*r? describes the repetition_penalty parameter. If it r1 there is no repetition penalty. | |||
*n? describes the no_repeat_ngram_size parameter. If it is n0 there is no ngram size restriction. | |||
<gallery mode="slideshow"> | |||
File:Boxplots.PNG|Mean Opinion score and Ranking (fig.1) | |||
File:Real_vs_generated.PNG| Real VS Generated Biograpy (fig.2) | |||
File:rank_freq.PNG| Ranking Frequency for each Setting (fig.3) | |||
</gallery> | |||
If we refer to the mean opinion score (MOS) [fig.1], two settings seem to give the best result, "V1_b3_r3_n0" and "V2_b3_r3_n0", the second one being slightly better. But if we look at the ranking, the first one as far better rankings. One of the reasons would be that even is the v2 model as a better MOS, it has a higher variance. In fact we can see that the models applying the ngram size restriction have less variance, we could assume that this parameter gives a more consistent generation quality than the repetition penalty parameter. | |||
In one of the section of the assessment survey, we introduced a real Wikipedia biography to test how the generated biography would perform compared to a real one. Unsurprisingly, the real biography got the better scores by far[fig.2]. But one interesting element is to look at the score given by the experts individually. We notice that the scores of the real biography are consistently high, but other generations got really good score from some experts, even better than the real biography. | |||
This would lead us to the conclusion that the quality of the generated biographies is difficult to assess and highly subjective, depending on the point of view of the reader on what makes a good biography. But consistency in the generation model can improves the overall quality of the generated biographies. | |||
== Deliverables == | == Deliverables == | ||
* Source code: https://github.com/Glorf/fdh-wikibio | |||
* Final model: https://huggingface.co/mbien/fdh-wikibio | |||
* Production website: https://wikibio.mbien.pl/ | |||
== Limitations and conclusions == | |||
While the achieved results are promising, there are many areas which might be further investigated and which might allow the significant improvements in term of quality of the generated biography. | |||
* we used GPT2-medium due to hardware limitations. The use of GPT2-large, or even GPT3 if OpenAI plans to actually release it anytime in the future, might significantly improve the generation result "for free". | |||
* Some entries, especially the lists of works, are disrupted by wikipedia Python package, and are space-separated lists instead of bullet points. It might be profitable to download the full wikipage and prepare the post-processing on our own, or even to train the model end-to-end on the whole page structure as-is. | |||
* it should be tested whether using more biographies for training (not only the citizens of the Republic of Venice), gives better or worse results. On one hand, more data is always pleasant for deep learning model. On the other, the model might learn and reproduce historical facts and situations very different from the expected life of the citizen of Republic of Venice. This also includes other wikis beyond wikipedia. | |||
* the idea of date adjustment can be eventually considered. However, it's not easy to implement, as the facts written in the biographies have a tendence to go beyond the lifespan of the person (eg. the summary of life of the children is often present at the end of the biography). The significant problem is also the fact of model not understanding the expected social age thresholds, eg. while the life events generally keep the life span, it's not possible to become the bishop at the age of 8. Or run the diplomatic relations with Rome at the age of 3. | |||
* the dedicated NER annotated on real wikipedia could allow the article to look more like the real one by providing links to many different wikipedia facts without limiting on places and organizations. | |||
Anyway, we are very satisfied with the results and we think that overcoming these problem is rather a matter of project time constraints than the technical possibilities. Looking forward to see the automatic biography generation present on the wikipedia of the future! :) | |||
== Trivia == | |||
After setting everything up, we googled randomly for WikiBio, and found that there was a dataset for table-to-text generation (so, very similar task) created just two years ago, with the same name! https://www.semanticscholar.org/paper/Table-to-text-Generation-by-Structure-aware-Seq2seq-Liu-Wang/3580d8a5e7584e98d547ebfed900749d347f6714 | |||
We promise there was no naming inspiration, and it's quite funny to see that coincidence | |||
Latest revision as of 15:12, 14 December 2020
Our first motivation for the project was to explore the possibilities of natural-language generation. Having at our disposal a big and accessible database like is Wikipedia, we wanted to generate a Wikipedia page that is written as human-like as possible. Our first challenge was to define our training dataset. To do this at first we wanted to use English Wikipedia pages of people who lived in Venice, but we soon realized that the criteria wasn't precise enough and included a large period of time. Therefore we restrained it to the people who where citizens of the Venice Republic. This criteria is precise enough to be registered in the Wikipedia information and would fit the image of a person living during the Middle-Age in Venice (Since the Venice Republic existed from 697 AD until 1797 AD).
In order to select the training data, we used the structural data of the Wikidata dataset that is linked to the corresponding Wikipedia page. During the data retrieval process, we noticed that from the 3 thousands entries on the Wikidata, only half of them had a corresponding English Wikipedia page. They are multiple reasons for this but it is mainly due to the fact that they are only available from a Wikipedia in an other language (mostly in Italian) and also the fact that the two platforms (Wikipedia and Wikidata) are complementary and publishing content on one platform will not directly create any content on the other.
For that reason we decided that the final goal of our project would be to populate a Wiki website with English biographies generated from the structured data of the Wikidata entries that are missing an English Wikipedia page. We will also explore the achieved results by evaluating the generated biographies using both automatic metrics and human opinion scores.
The final result of our project is easiest explorable on the website https://wikibio.mbien.pl
Project plan
| Week | Dates | Goals | Result |
|---|---|---|---|
| 1 | 8.10-15.10 | Exploring data souces | Selected Wikipedia + Wikidata |
| 2 | 15.10-22.10 | Matching textual and structural data | Wikipedia articles matched with wikidata |
| 3 | 22.10-29.10 | First trained model prototype | GPT-2 was trained on english data |
| 4 | 29.10-5.11 | Acknowledge major modelling problems | GPT-2 was trained in Italian, issues with Wikipedia pages completion and Italian model performances |
| 5 | 5.11-12.11 | Code clean up, midterm preparation | Improved sparql request |
| 6 | 12.11-19.11 | Try with XLNet model, more input data, explore evaluation methods | Worse results with XLNet (even with more input data), Subjective quality assessment and Bleu/Gleu methods |
| 7 | 19.11-26.11 | Start evaluation surveys and automatic evaluation, improve GPT-2 input data | Survey started, introduced full-article generation with sections |
| 8 | 26.11-3.12 | Productionalization, finish evaluation | Created wikibio.mbien.pl to present our results and started working on API for page uploads |
| 9 | 3.12-10.12 | Productionalization, evaluation analysis | Finished the wikipage, uploaded code and prepared the presentation slides |
| 10 | 10.12-16.12 | Final Presentation | Who knows? |
Data sources

In this project, we made use of two different data sources: Wikidata and Wikipedia
Wikidata
Wikidata was used to gather the structured information about the people who lived in the Republic of Venice. To gather this data from wikidata, a customizable SPARQL query is used on the official wikidata SPARQL API. Only two strict constraints were set for data filtering:
- Instance of (wdt:P31), human (wd:Q5)
- Citizenship (wdt:P27), Republic of Venice (wd:Q4948)
Optionally, following data was also gathered - we used it for generation whenever they existed in the data
- ID of the object in the wikidata
- itemLabel (wikibase:label) - generally either equal to the person's full name, or the wikidata ID
- itemDescription (schema:description) - short, generally two-word, description of the person
- birth year (wdt:P569)
- death year (wdt:P570)
- profession (wdt:P106)
- last name (wdt:P734)
- first name (wdt:P735)
- link to picture in commons (wdt:P18)
Wikipedia
Wikipedia was used to match the wikidata entries with the unstructured text of the article about that person. The "Wikipedia" package for python was used to find the matching pairs and then to extract the Wikipedia articles matching the entries.
Generation methods
The output of the above data sources is prepared jointly in the following manner:
- All the structured entries are transformed to text, by putting the custom control token in front of them and then concatenating them together
- The resulting text is the training sample for the model
We considered two language model architectures: XLNet and GPT-2. We used Huggingface Transformers library backed with PyTorch in both cases, as the SOTA environment for training and sharing the Transformers models. The comparison of the models and reason of selection of GPT-2 is described below:
XLNet
XLNet is a late-2019 bi-directional language model, mostly used for tasks like sentiment analysis, classification and word correction. However, it was interesting for us due to its possibility to train on and generate text samples of virtually infinite length.
Pros:
- variable text length
- modern architecture
Cons:
- bi-directionality is not of much use here and takes more memory
- considerably lower performance on text generation tasks than GPT-2
Finally, our tests has shown that we should not consider XLNet for our biography generation effort, for a number of reasons:
- there is no text sample length limit, but the GPU RAM is not, which makes the limitation to ~1500 tokens required anyway
- the model performs poorly with short inputs
- the text is gramatically correct but the coherence with semistructured data is very bad, supposedly due to bi-directional nature of the model
GPT-2
GPT-2 is an early-2019 Causal (left-to-right) Language Model. It it widely used for language modeling for text generation, and as such it was perceived as the best shot to get the decent language modeling performance.
Pros:
- modern architecture
- left-to-right: memory-efficient
- widely used for text generation
Cons:
- fixed 1024 tokens context frame
The model performed well to understand the semi-structured input based on the underlying wikidata. It allowed generating short, but consistent biographies.
Example generation output
- Input: <|start|> Marco Polo <|description|> Painter <|professions|> Painter, Writer <|birth|> 1720 <|death|> 1793 <|summary|>
- Output: Marco Polo (1720 – 1793) was a German painter of a distinguished life of high quality. In 1740 he was the first to paint in an Italian Renaissance style. He served as the painter of Giovanni Venez in Venice; his brother was Giovanni Magnan and daughter was a painter of his own time, Marco Polo. During his career he collaborated with the great Venetian painter Giovanni Battista Gugliati in the work for the Porte della Prudina, which was published in 1714. After his death, he would leave his paintings at Venice for the Palace of Santa Martina.
Generation hyperparameters tuning
In this section, we elaborate on the possible generation parameters, and their effect on the final model output. The comparison is based on our understanding of these metrics, proposed in the document "How to generate" by Huggingface: https://huggingface.co/blog/how-to-generate
- Repetition penalisation:
The generation pipeline implements two methods to control the repetitions in the generated text. First, repetition_penalty, is a penalty metrics which decreases the score of the repeated token with each consecutive occurence. Then, no_repeat_ngram_size bans the use of the ngrams more than once by setting their probability to zero if they already exist in the text. In the evaluation section, we show how use of these two methods influence the opinion score on the model generation.
- Beam Search:
This greedy generation method is famous for giving very good, but very boring text results. We used it extensively for the generation of biographies for human evaluation. However, as the beam search practically eliminates the randomness of the results given its greedy approach, this method was not used for the wiki biographies generation.
- Top-K, top-P sampling:
Method which selects random token out of K tokens of highest probability, but only if their probability is over the P threshold. While the results are not as good as the ones of beam search, the resulting articles are much more interesting and, thanks to the randomness, can be generated many times with different results. This method was used to generate wikibio in the final generation pipeline.
Productionalization

Platform
To serve the generated biographies, we created the MediaWiki website: https://wikibio.mbien.pl/ The platform was based on the private server, running the docker-compose stack. The used containers were:
- mediawiki 1.35 from https://hub.docker.com/_/mediawiki
- mariadb 10.5 from https://hub.docker.com/_/mariadb
The server was also running traefik 1.7 as an ingress gateway and TLS terminator.
Functionalities such as Infobox:Person, required significant manual modifications to the vanilla MediaWiki installation. To enable this functionality, it was required to perform all the operations described in the following tutorial: https://www.mediawiki.org/wiki/Manual:Importing_Wikipedia_infoboxes_tutorial. Finally, the logos and favicons were replaced with the coat of arms of Republic of Venice, to give the platform more pleasant look.
Automatic generation pipeline
The final generation pipeline was a complex, multi-phase operation. While the survey-based evaluation of our model was meant to show the overall performance, here we wanted to get only the well-conditioned biographies, ready to be served to the users. The overall pipeline is visible in the following diagram, with details explained in the further subsections
Post-processing wikidata
In general, itemLabel extracted from the wikidata was meant to contain the person full name. However, it was not always the case. Some labels contained the wikidata ID of the entry. These samples were found, and, whenever possible, their labels were replaced with the first and last name acquired via the data optional fields. If those fields were not existing either, the sample was dropped, having not enough information to start the generation.
Generation with structural accuracy score
After the data was ready, we used our fine-tuned GPT2-medium model to generate 20 biographies. The generation sampling setup was top_p=0.97, top_k=10. Each of the generated biographies was then checked for validity:
- Whether it was complete - if it has less than 1024 tokens, or if the last token is the pad or end token.
- Whether there were no duplicate sections
- Whether there were no generated control tokens in the textual part of the biography
Then, the structural accuracy scores were calculated for each of the remaining biographies (see the metric details in evaluation section). If the best biography reached over 0.95 structural accuracy, the biography was accepted. Otherwise, the threshold was decreased by 0.05, and the generation procedure was repeated.
Procedural enrichment of the output
The output of the generation was plain text divided into sections. It was important to increase the article plausibility using several post-processing methods:
- First, the text was processed using SpaCy NER model en_core_web_lg. The entities related to locations (GPE) and to the universities (ORG with "university" substring) were manually tested to perform well without further NER training. Each detected entity was replaced with link to the wikipedia page, without checking the actual existence of such a page. The links were intentionally made to look like the internal links to the existing pages on WikiBio. This made the articles more convincing, and in most cases, the links were actually working.
- Finally, the infobox was created using the imported Wikipedia "Template:Infobox person". Besides all the information acquired from the wikidata and used for generation, the biography was also enriched with the picture, whenever it was present in the original wikidata. Thanks to the MediaWiki's InstantCommons feature, it was not required to gather the images: they were forwarded automatically from Wikimedia Commons based on the provided image name.
Wikipedia page upload using Pywikibot
The final biography text, consisting of plain-text with NER-based links and infobox, was then saved as a WikiBio page. pyWikibot library was used to build a MediaWiki bot and the special bot account credentials were generated for this occasion. The pipeline was running for about 17 hours in total, on Google Colab Tesla V100, resulting in 1389 generated biographies.
Evaluation

Objective (automatic)
We used three different approaches for automatic evaluation. The translation metrics such as BLEU or GLEU are SOTA for generic text generation tasks, therefore there was a possibility that they could work in this case as well. Then, we implemented a naive check method, named structural accuracy, which was used to assess the biography quality in the final generation task. Finally, we worked on the new metric, codenamed (Top-TIKPIT Neighbours), which was meant to be tailored for the specifics of our task and better explain the differences between the original and generated data in a visual way.
Translation metrics
We wanted to use translation metrics (BLEU and GLEU) in the manner typical for this kind of tasks. That is, we generated multiple biographies, which we put as a reference to test the hypothesis - real biography. This way, the real biography should score higher given the better reference biographies, which implies the better generation in the indirect manner. Unfortunately, the metric didn't provide any conclusive results. The variance of the scores was very high (from 0.01 to 0.32), and the metric have sometimes scored better on the samples, which we perceived as much worse. It became clear that in encyclopedic articles, the linguistic smoothness and use of specific words is not as important as the fact coherence and ideas abstract from the linguistic perspective, such as time spans or event precedence. We decided to continue our efforts with other metrics.
Structural accuracy
The structural accuracy is a naive, but very efficient method we used to evaluate the coherence between the provided data and generated biography. The method was successful enough to be incorporated into the production pipeline. This is how it works, in three steps:
- The tokens are removed from input structure:
"<|start|> Marco Polo <|description|> Painter <|professions|> Painter, Writer <|birth|> 1720 <|death|> 1793 <|summary|>" -> "Marco Polo Painter Painer, Writer 1720 1793"
- The remaining structure is lowercased and split into tokens. Only alphanumeric characters are kept, stopwords are removed using NLTK english stopwords list:
"Marco Polo Painter Painter, Writer 1720 1793" -> ["marco", "polo", "painter", "writer", "1720", "1793"]
- The generated text is evaluated for presence of the listed words. The percentage of the words present in the text become the score.
For example generation output from section "Generation methods": The name and years are correct, however there is no mention of "writer" - the score is 0.83. This example shows clearly, how this rough approximation of the biography "validity" can be a useful tool - it correctly scored the biography of painter-writer lower, because the generated text was only about the painter.
KNN over top TF-IDF Keywords for Profession in Time (Top-TIKPIT) matrix (Top-TIKPIT Neighbours)

The method codenamed Top-TIKPIT was our final, last-minute idea for reasonable and explainable model evaluation. The same algorithm is used separately on original and generated data, and then the results are compared:
- Split the dataset into parts, based of the person profession
- For every part, split it once more, based on the century the person lived in ((birth+death)/2 if both dates are available)
- Join all the text in the smallest parts. Flatten the array so that the number of strings is professions_num*centuries_num
- Treat every text as a doc for TF-IDF vectorizer, fit and transform the data
- For every document, extract top TF-IDF tokens
This Top-TIKPIT matrix can be easily visualized, preferably with X being the time and Y being the occupation. Note that the axes are discrete. The time span and number of top TF-IDF tokens can be customized. The performance of the model can be assesed based on how well it manages to reproduce important topics for the class of citizen of the given century. The metric can be assessed either visually, or using multilabel accuracy metric. There is also an area for further work, where we can try to make the axes continuous and assess the biography quality by checking the Top-TIKPIT for the K-Nearest-Neighbors
Subjective (survey)
With objective metrics we were more or less able to evaluate the validity and the correctness of the generated biographie, but we had a hard time to define exactly what makes a good biography and to find a metric that would assess the quality of the generation. Therefore, we conducted a qualitative assessment survey. We generated a biography from six random entries on the Wikidata that don't have an English Wikipedia page for each different models that we wanted to test, five models in total. Comparing the 5 biographies generated, the experts would first give a score from 1 to 10 to each biography and then rank them in order of quality. This assessment compares mainly the repetition penalisation parameters.
The result of the assessment is shown in the following figures. The two featured models (V1 and V2) are quite similar, beside that V2 as more more parameters. Each setting is described with his name, for example "V1_b3_r3_n0".
- v1/v2 describes wich model was used.
- p? describes the top-P sampling parameter. If it is p0 there top p sampling wasn't used.
- b? describes the number of beams for beam search.Top_p and num_beam are incompatible.
- r? describes the repetition_penalty parameter. If it r1 there is no repetition penalty.
- n? describes the no_repeat_ngram_size parameter. If it is n0 there is no ngram size restriction.
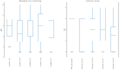
Mean Opinion score and Ranking (fig.1)

Real VS Generated Biograpy (fig.2)

Ranking Frequency for each Setting (fig.3)



If we refer to the mean opinion score (MOS) [fig.1], two settings seem to give the best result, "V1_b3_r3_n0" and "V2_b3_r3_n0", the second one being slightly better. But if we look at the ranking, the first one as far better rankings. One of the reasons would be that even is the v2 model as a better MOS, it has a higher variance. In fact we can see that the models applying the ngram size restriction have less variance, we could assume that this parameter gives a more consistent generation quality than the repetition penalty parameter.
In one of the section of the assessment survey, we introduced a real Wikipedia biography to test how the generated biography would perform compared to a real one. Unsurprisingly, the real biography got the better scores by far[fig.2]. But one interesting element is to look at the score given by the experts individually. We notice that the scores of the real biography are consistently high, but other generations got really good score from some experts, even better than the real biography.
This would lead us to the conclusion that the quality of the generated biographies is difficult to assess and highly subjective, depending on the point of view of the reader on what makes a good biography. But consistency in the generation model can improves the overall quality of the generated biographies.
Deliverables
- Source code: https://github.com/Glorf/fdh-wikibio
- Final model: https://huggingface.co/mbien/fdh-wikibio
- Production website: https://wikibio.mbien.pl/
Limitations and conclusions
While the achieved results are promising, there are many areas which might be further investigated and which might allow the significant improvements in term of quality of the generated biography.
- we used GPT2-medium due to hardware limitations. The use of GPT2-large, or even GPT3 if OpenAI plans to actually release it anytime in the future, might significantly improve the generation result "for free".
- Some entries, especially the lists of works, are disrupted by wikipedia Python package, and are space-separated lists instead of bullet points. It might be profitable to download the full wikipage and prepare the post-processing on our own, or even to train the model end-to-end on the whole page structure as-is.
- it should be tested whether using more biographies for training (not only the citizens of the Republic of Venice), gives better or worse results. On one hand, more data is always pleasant for deep learning model. On the other, the model might learn and reproduce historical facts and situations very different from the expected life of the citizen of Republic of Venice. This also includes other wikis beyond wikipedia.
- the idea of date adjustment can be eventually considered. However, it's not easy to implement, as the facts written in the biographies have a tendence to go beyond the lifespan of the person (eg. the summary of life of the children is often present at the end of the biography). The significant problem is also the fact of model not understanding the expected social age thresholds, eg. while the life events generally keep the life span, it's not possible to become the bishop at the age of 8. Or run the diplomatic relations with Rome at the age of 3.
- the dedicated NER annotated on real wikipedia could allow the article to look more like the real one by providing links to many different wikipedia facts without limiting on places and organizations.
Anyway, we are very satisfied with the results and we think that overcoming these problem is rather a matter of project time constraints than the technical possibilities. Looking forward to see the automatic biography generation present on the wikipedia of the future! :)
Trivia
After setting everything up, we googled randomly for WikiBio, and found that there was a dataset for table-to-text generation (so, very similar task) created just two years ago, with the same name! https://www.semanticscholar.org/paper/Table-to-text-Generation-by-Structure-aware-Seq2seq-Liu-Wang/3580d8a5e7584e98d547ebfed900749d347f6714 We promise there was no naming inspiration, and it's quite funny to see that coincidence