Alignment of XIXth century cadasters: Difference between revisions
Marin.piguet (talk | contribs) |
|||
| (117 intermediate revisions by 2 users not shown) | |||
| Line 2: | Line 2: | ||
== Introduction == | == Introduction == | ||
About a thousand of French napoleonian cadasters have been scanned and need from now to be aligned. A lot of different cities are included in this catalogue as La Rochelle, Bordeaux, Lyon, Lille, Le Havre and also cities that are no longer under French juridiction as Rotterdam. | About a thousand of French napoleonian cadasters have been scanned and need from now to be aligned. A lot of different cities are included in this catalogue as La Rochelle, Bordeaux, Lyon, Lille, Le Havre and also cities that are no longer under French juridiction as Rotterdam. | ||
| Line 10: | Line 7: | ||
Similarly to the work that had been done by the [https://en.wikipedia.org/wiki/Venice_Time_Machine Venice Time Machine] project, the idea is to attach every maps from a cadaster in order to get a single map of each city. | Similarly to the work that had been done by the [https://en.wikipedia.org/wiki/Venice_Time_Machine Venice Time Machine] project, the idea is to attach every maps from a cadaster in order to get a single map of each city. | ||
The main challenge for this project is the automatisation of this process, despite all inconsistencies in the maps, in terms of scale, orientation or conventions. | The main challenge for this project is the automatisation of this process, despite all inconsistencies in the maps, in terms of scale, orientation or conventions. Indeed, even if the instructions for the realisation of the maps were quite strict, some differences might last. For example, if there were nothing to show in some areas, geometers were allowed to represent them at larger scale. Other example, maps are not always oriented top-north (which is even not always indicated). | ||
== Deliverables == | == Deliverables == | ||
This project provides an exploration of possible automation leads to align cadastres, as well as the development of an interface (in the form of a Jupyter Notebook) to supervise this task. | |||
Together with this report, the deliverables are: | |||
* [https://github.com/noe-d/AlignmentTool AlignmentTool]: the tool developed to supervise cadastres' alignment. GitHub repository: https://github.com/noe-d/AlignmentTool. | |||
* La Rochelle's 1811 cadastres case study (hosted on the shared [https://drive.google.com/drive/u/0/folders/0AKml0aowcS4wUk9PVA Google Drive]): | |||
** predicted lines in La Rochelle's 1811 cadastres. | |||
** graph storing the matches between adjacent cadastres in JSON format. | |||
** recomposed image of La Rochelle's intramural cadastres. | |||
== Project setup == | == Project setup == | ||
| Line 27: | Line 24: | ||
=== Methods exploration on Berney's cadaster === | === Methods exploration on Berney's cadaster === | ||
For the primary research of methods to reattach cadastral maps, the so called ''cadastre Berney'' from Lausanne (1827) has been used, as long as the ground truth for this particular case is known and lot of processing steps (as lines and classes predictions) have already been made. The first exercise has been made on the two first maps, using the lines prediction files. The quandary was to be able to detect the common parts of these two maps, in this case the [https://www.openstreetmap.org/way/37042420#map=18/46.52000/6.63295 ''Rue Pépinet''] and the top of [https://www.openstreetmap.org/way/86932058#map=18/46.51967/6.63198 ''Rue du petit chêne'']. Many different methods have been tested for that task, mainly with help of the openCV python library. The researches have focused on [https://en.wikipedia.org/wiki/Scale-invariant_feature_transform | For the primary research of methods to reattach cadastral maps, the so called ''cadastre Berney'' from Lausanne (1827) has been used, as long as the ground truth for this particular case is known and lot of processing steps (as lines and classes predictions) have already been made. The first exercise has been made on the two first maps, using the lines prediction files. The quandary was to be able to detect the common parts of these two maps, in this case the [https://www.openstreetmap.org/way/37042420#map=18/46.52000/6.63295 ''Rue Pépinet''] and the top of [https://www.openstreetmap.org/way/86932058#map=18/46.51967/6.63198 ''Rue du petit chêne'']. Many different methods have been tested for that task, mainly with help of the OpenCV<ref name="openCV">Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org</ref> python library. The researches have focused on [https://en.wikipedia.org/wiki/Scale-invariant_feature_transform scale invariant feature transform (SIFT)], [https://en.wikipedia.org/wiki/Generalised_Hough_transform General Hough Transform (GHT)]<ref name="ght">Ballard, D. H. (1981). Generalizing the Hough transform to detect arbitrary shapes. In Pattern Recognition (Vol. 13, Issue 2, pp. 111–122). Elsevier BV. doi:[https://doi.org/10.1016/0031-3203(81)90009-1 10.1016/0031-3203(81)90009-1]</ref> and [https://en.wikipedia.org/wiki/Template_matching Template Matching (TM)]. The method that gave the most satisfying results (in terms of final output and computation time) was the template matching. | ||
=== Template matching principle === | === Template matching principle === | ||
Template matching is an OpenCV<ref name="openCV">Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org</ref> function provided under the name [https://docs.opencv.org/4.x/df/dfb/group__imgproc__object.html#ga586ebfb0a7fb604b35a23d85391329be '''cv.matchTemplate()''']. It takes as an imput a large scale image and smaller one, called ''template'', that it will try to find in the first image. Concretely, the function slides the template through the initial image and for each position, gives a score of closeness. Note that the template always fully overlap the image, therefore the template must be fully included in the image. The function gives then as an output a matrix with score for each position. It then easy to find the position of the best score. | Template matching is an OpenCV<ref name="openCV">Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org</ref> function provided under the name [https://docs.opencv.org/4.x/df/dfb/group__imgproc__object.html#ga586ebfb0a7fb604b35a23d85391329be '''cv.matchTemplate()''']. It takes as an imput a large scale image and smaller one, called ''template'', that it will try to find in the first image. Concretely, the function slides the template through the initial image and for each position, gives a score of closeness. Note that the template always fully overlap the image, therefore the template must be fully included in the initial image. The function gives then as an output a matrix (an example of such a heatmap can be seen below) with score for each position. It is then easy to find the position of the best score. | ||
The function provides several ways to compute that score. The one used for this project is the so called TM_CCOEFF_NORMED, defined as : | The function provides several ways to compute that score. The one used for this project is the so called TM_CCOEFF_NORMED, defined as : | ||
| Line 44: | Line 41: | ||
and where ''T'' and ''I'' refer to pixels of the template, respectively initial, images, and finally ''w'' and ''h'' are width, respectively height, of the template. | and where ''T'' and ''I'' refer to pixels of the template, respectively initial, images, and finally ''w'' and ''h'' are width, respectively height, of the template. | ||
Template matching is known to have better results on simpler images exhibiting clear contrasts between shapes<ref name="TMboost">Hashimoto, M., Sumi, K., Sakaue, Y., & Kawato, S. (1992). High-speed template matching algorithm using information of contour points. In Systems and Computers in Japan (Vol. 23, Issue 9, pp. 78–87). Wiley. doi:https://doi.org/10.1002/scj.4690230908.</ref>. | |||
It is therefore a wise decision to preprocess the cadastres in order to bring their main features out. Thus, TM is performed here on the detected lines (see [[#Lines_detection_process| lines detection section]] for more details) when available, or on cadastres' edges otherwise. | |||
=== First reattachment of two cadastral maps === | === First reattachment of two cadastral maps === | ||
Now that a sufficiently satisfying function had been found, the first milestone of this project was the first reattachment of two cadastral maps. The strategy was to manually cut a template in one of the maps and find the best match in the other one. Attaching the two maps together is then an almost straightforeward task, as long as the lines prediction files are only black (0) or white (255) pixels, and the final result is just the sum of the two of them adapted with the best matching position. | |||
<!-- | <!-- | ||
| Line 63: | Line 61: | ||
[[Image:cv2_TM_CCOEFF_NORMED_match_001_to_002_heatmap.png|420px|right|thumb|Heatmap of the Template Matching process and detected template on the target image.]] | [[Image:cv2_TM_CCOEFF_NORMED_match_001_to_002_heatmap.png|420px|right|thumb|Heatmap of the Template Matching process and detected template on the target image.]] | ||
| Line 69: | Line 67: | ||
[[Image:Recollage_002_to_001.png|x400px|thumb|center|Alignment of Berney's 1827 cadastral maps 001 and 002]] | [[Image:Recollage_002_to_001.png|x400px|thumb|center|Alignment of Berney's 1827 cadastral maps 001 and 002]] | ||
== | == Organisation == | ||
As suggested before, the first steps of this project were quite empiric. Almost no step was automitzed and there were no other method than giving the two first maps to the function we were trying to use and hope that the result would be sufficiently satisfying and quickly computed. This finally gave us an heuristic argument to choose the template matching function. | |||
But after this liminary choice, many challenges were still standing in front of us in order to perform large scale cadastres alignment. | |||
* First, it was necessary to find criteria for the template’s extraction, ie. could we find a way that the pipeline detects by itself the common part of two maps ? | |||
* Secondly, the orientation and scale differences in-between the maps were still problematic. Again, shall we indicate those variation « by hand » or could the pipeline understand it by itself ? | |||
* A third problem was the capacity of our pipeline to be sufficiently precise to close loops of maps correctly, ie. would errors in successive matching cancel each other or propagate such that it would be impossible to place correctly the last map of a loop ? | |||
* Finally, the probably most prominent challenge was our lack of metric. Indeed, the appreciation of the quality of the result of the matching was left to our own vision of the result. It would have been really beneficial to find an objective way to define the quality of the result, thanks to a metric. | |||
The following table summaries the different ways we tried to handle those difficulties. Obviously, some methods were abandoned and some have been used until the end. | |||
{| class="wikitable" | {| class="wikitable" style="margin:auto; border: none;" | ||
|- | |- | ||
! | ! | ||
! Paradigm | |||
! Matching method | |||
! Template extraction | |||
! Data structure | |||
! Growth | |||
! Lines detection | |||
|- | |- | ||
| Week 4 | | Week 4 | ||
| rowspan="7" | Automation | |||
| SIFT | |||
| style="text-align:center;" | - | |||
| rowspan="4" style="text-align:center;" | - | |||
| rowspan="2" | 1 to 1 | |||
| rowspan="7" style="text-align:center;" | - | |||
|- | |- | ||
| Week 5 | | Week 5 | ||
| SIFT and GHT | |||
| rowspan="3" | Manual | |||
|- | |- | ||
| Week 6 || GHT and TM || | | Week 6 | ||
| rowspan="2" | GHT and TM | |||
| rowspan="3" | Semi-automated 1 to 1 | |||
|- | |- | ||
| Week 7 | | Week 7 | ||
|- | |- | ||
| Week 8 || | | Week 8 | ||
| rowspan="7" | Template Matching | |||
| rowspan="3" | Manual and <br> automated along lines | |||
| rowspan="4" | Dictionary | |||
|- | |- | ||
| Week 9 | | | Week 9 | ||
| rowspan="2" | 1 to 1 <br> or 1 to N adjacents | |||
|- | |- | ||
| Week 10 | | Week 10 | ||
|- | |- | ||
| Week 11 | |||
| rowspan="4" | Supervision | |||
| rowspan="4" | Manual with user tool | |||
| rowspan="4" | 1 to 1 <br>1 to N recomposition | |||
| rowspan="2" | First attempts on La Rochelle | |||
|- | |- | ||
|Week | | Week 12 | ||
| | | rowspan="3" | Network | ||
|- | |- | ||
|Week | | Week 13 | ||
| | | rowspan="2" | Final steps on La Rochelle, <br>with Google Colab and sliced images | ||
|- | |- | ||
| Week 14 | |||
|Week 14 | |||
|} | |} | ||
| Line 139: | Line 149: | ||
To do so, an imaginary path parametrised by an angle is drawn from the center of the cadastre to its edge. Pixels values along this path are extracted and used to retrieve the coordinates of the last non-zero pixel value (ie. extracted line on the cadastre). A template can then be extracted around this point. | To do so, an imaginary path parametrised by an angle is drawn from the center of the cadastre to its edge. Pixels values along this path are extracted and used to retrieve the coordinates of the last non-zero pixel value (ie. extracted line on the cadastre). A template can then be extracted around this point. | ||
The function automating this task takes an integer ''N'' as argument that defines the number of templates to be extracted. Templates are then extracted along paths parametrised by the linear division of the circle in ''N'' pieces (see [https://github.com/noe-d/AlignmentTool/blob/ | The function automating this task takes an integer ''N'' as argument that defines the number of templates to be extracted. Templates are then extracted along paths parametrised by the linear division of the circle in ''N'' pieces (see [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L63 <code>extract_templates</code>]). Examples are shown in the left hand side plot present in the figure on the right. | ||
Nevertheless these plot mainly highlight the fragility of the matching method. Indeed they underline that the TM score doesn't align with the human understanding of the problem. Moreover, as TM is highly dependent on the templates, this approach is highly dependent on the chosen number of extracted templates ''N''. For example here extracting 9 templates resulted in a coherent best match but extracting one less template yielded wrong results. | Nevertheless these plot mainly highlight the fragility of the matching method. Indeed they underline that the TM score doesn't align with the human understanding of the problem. Moreover, as TM is highly dependent on the templates, this approach is highly dependent on the chosen number of extracted templates ''N''. For example here extracting 9 templates resulted in a coherent best match but extracting one less template yielded wrong results. | ||
| Line 153: | Line 163: | ||
=== Peripheral growth === | === Peripheral growth === | ||
Both of the previously stated methods ([[#Automatic_template_extraction| Automatic template extraction]] and [[#Orientation_and_scale_integration| scale and orientation invariant TM]]) were then combined in an algorithm anchoring iteratively adjacents cadastres to the already integrated ones to spread the covered area. The list of adjacent cadastres were manually encoded and the parameters manually fine-tuned to reach meaningful results over several cadastres, see for example the left hand-side figure below. However this method demonstrated poor reliability and generalisation power, as illustrated on the right hand-side. There template 006 is wrongly matched on 008 and any additional consideration on this cadastre would be meaningless and detrimental to the general workflow. | Both of the previously stated methods ([[#Automatic_template_extraction|Automatic template extraction]] and [[#Orientation_and_scale_integration| scale and orientation invariant TM]]) were then combined in an algorithm anchoring iteratively adjacents cadastres to the already integrated ones to spread the covered area. The list of adjacent cadastres were manually encoded and the parameters manually fine-tuned to reach meaningful results over several cadastres, see for example the left hand-side figure below. However this method demonstrated poor reliability and generalisation power, as illustrated on the right hand-side. There template 006 is wrongly matched on 008 and any additional consideration on this cadastre would be meaningless and detrimental to the general workflow. | ||
<gallery caption="Iterative growth with successive anchors 001, 009, 010 and 008. Taking into account slight variations in orientation and two scales." mode="packed-hover" heights="430px" class="center"> | <gallery caption="Iterative growth with successive anchors 001, 009, 010 and 008. Taking into account slight variations in orientation and two scales." mode="packed-hover" heights="430px" class="center"> | ||
| Line 159: | Line 169: | ||
Image:automatic_001_009_010_008_adjacents.png|After matching 006 onto 008. Semantically wrong match. | Image:automatic_001_009_010_008_adjacents.png|After matching 006 onto 008. Semantically wrong match. | ||
</gallery> | </gallery> | ||
=== Limitations === | === Limitations === | ||
| Line 177: | Line 185: | ||
Facing the incapacity to define a convincing metric, we decided to shift paradigm and directly involve human understanding in the loop by developing a [[#AlignmentTool| tool]] to supervise the alignment task. | Facing the incapacity to define a convincing metric, we decided to shift paradigm and directly involve human understanding in the loop by developing a [[#AlignmentTool| tool]] to supervise the alignment task. | ||
<!-- | <!-- | ||
| Line 196: | Line 192: | ||
== AlignmentTool == | == AlignmentTool == | ||
The [https://github.com/noe-d/AlignmentTool/ AlignmentTool] was developed to offer a highly supervised method to perform the cadastres' alignment. | |||
The backend processes are mainly handled through OpenCv<ref name="openCV">Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org</ref>, the data structure is managed with NetworkX<ref name="networkx">Aric A. Hagberg, Daniel A. Schult, & Pieter J. Swart (2008). Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference (pp. 11 - 15). Documentation: https://networkx.org/documentation/stable</ref>, and the Notebook interface relies on jupyter-innotater<ref name="jupyter-innotater">Lester, D (danlester). (2021). jupyter-innotater. GitHub Repository: https://github.com/ideonate/jupyter-innotater.</ref>. The architecture and proceeding of each of these components are detailed below. Finally, the results of the [[#Case_Study:_La_Rochelle_1811| proof of concept]] undertook on La Rochelle's Napoleonic cadastres from 1811 within [https://fr.geneawiki.com/index.php/Fortifications_de_La_Rochelle#Les_enceintes_des_XVIe_et_XVIIe_si.C3.A8cles.5B2.5D Ferry's rampart] are described and illustrated. | |||
The [https://github.com/noe-d/AlignmentTool | |||
The backend processes are mainly handled through OpenCv<ref name="openCV">Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org</ref>, the data structure is managed with NetworkX<ref name="networkx">Aric A. Hagberg, Daniel A. Schult, & Pieter J. Swart (2008). Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference (pp. 11 - 15). Documentation: https://networkx.org/documentation/stable</ref>, and the Notebook interface relies on jupyter-innotater<ref name="jupyter-innotater">Lester, D (danlester). (2021). jupyter-innotater. GitHub Repository: https://github.com/ideonate/jupyter-innotater.</ref>. The architecture and proceeding of each of these components are detailed below. Finally, the results of the proof of concept undertook on La Rochelle | |||
=== Backbone === | === Backbone === | ||
| Line 225: | Line 202: | ||
[[Image:Rotated_template.png|x200px|thumb|right|Example of a rotated template with tagged points.]] | [[Image:Rotated_template.png|x200px|thumb|right|Example of a rotated template with tagged points.]] | ||
The matching model aims at finding two pairs of homologous points in the anchor and target cadastres (see [https://github.com/noe-d/AlignmentTool/blob/ | The matching model aims at finding two pairs of homologous points in the anchor and target cadastres (see [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L428 <code>get_target_homologous</code>]). It relies on TM (described [[#Template_matching_principle| above]]). On the anchor cadastres the tagged positions are the top-left and bottom-right corners of the extracted template. On the target one, the corresponding points are retrieved from the best match found. | ||
If both of the cadastres share the same orientation (ie. matches are evaluated without taking into account additional rotations), then the pixel associated with the top-left corner of the template corresponds to the location with the highest value computed through TM and the pixel associated with the bottom-right corner is given by adding the template width and height. | If both of the cadastres share the same orientation (ie. matches are evaluated without taking into account additional rotations), then the pixel associated with the top-left corner of the template corresponds to the location with the highest value computed through TM and the pixel associated with the bottom-right corner is given by adding the template width and height. | ||
If both of the cadastres don't share the same orientation, this task requires slightly more efforts. This procedure iteratively rotates the template, resulting in images of different shapes filled with void, and performs TM using these rotated templates (see [https://github.com/noe-d/AlignmentTool/blob/ | If both of the cadastres don't share the same orientation, this task requires slightly more efforts. This procedure iteratively rotates the template, resulting in images of different shapes filled with void, and performs TM using these rotated templates (see [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L339 <code>orientation_matching</code>]). Thus, the coordinates of the best match will correspond to the top-left corner of the best rotated template, which is no longer in line with the top-right corner of the extracted template. The new pixel coordinates corresponding to the orignial template top-left and bottom-right corners are retrieved by artificially rotating the original template and computing the displacement of specified points (see [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L383 <code>shift_template</code>]). | ||
An example of points tracking in the rotated templates is shown on the figure on the right. The figure below displays the results obtained through this method on a pair of non-aligned cadastres. | An example of points tracking in the rotated templates is shown on the figure on the right. The figure below displays the results obtained through this method on a pair of non-aligned cadastres. | ||
| Line 240: | Line 217: | ||
In the context of this project, homographies are restricted to Euclidean transformations (allowing rotations and translations but preserving the distance between every pair of points). However, as the rest of the implementation is more general, slight modifications of the homographies' computation could enable the intergration of more complex transformations (eg. affine or projective) within the pipeline. | In the context of this project, homographies are restricted to Euclidean transformations (allowing rotations and translations but preserving the distance between every pair of points). However, as the rest of the implementation is more general, slight modifications of the homographies' computation could enable the intergration of more complex transformations (eg. affine or projective) within the pipeline. | ||
The pairs of homologous points retrieved through the matching process allows to compute the corresponding homography between the anchor and target cadastres. On both images the pair of coordinates define a vector from the top right to the bottom left tags. As they are considered to refer to the same geographic entity, the cadastres can be re-oriented (relatively to one another) by calculating the angle α between these vectors. The translations in 𝑥 and 𝓎 are computed by comparing points corresponding to the top left corner in the anchor image and target one (after re-orientation). The homography matrix is then given by: | The pairs of homologous points retrieved through the matching process allows to compute the corresponding homography between the anchor and target cadastres. On both images the pair of coordinates define a vector from the top right to the bottom left tags. As they are considered to refer to the same geographic entity, the cadastres can be re-oriented (relatively to one another) by calculating the angle α between these vectors. The translations in 𝑥 and 𝓎, ''t<sub>𝑥</sub>'' and ''t<sub>𝓎</sub>'', are computed by comparing points corresponding to the top left corner in the anchor image and target one (after re-orientation). The homography matrix is then given by: | ||
| Line 246: | Line 223: | ||
This process is encoded in the function [https://github.com/noe-d/AlignmentTool/blob/ | This process is encoded in the function [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L514 <code>vector_alignment</code>]. It allows to turn the matches characterised by two pairs of homologous points into a transformation matrix, which can be applied on the target cadastre to obtain its composition with its anchor through [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L575 <code> warpTwoImages</code>] based on [https://docs.opencv.org/4.x/da/d54/group__imgproc__transform.html#gaf73673a7e8e18ec6963e3774e6a94b87 cv2.warpPerspective]. | ||
==== Propagation ==== | ==== Propagation ==== | ||
| Line 257: | Line 234: | ||
Thus, taking benefits of the network structure of the data (descibed [[#Network_structure| below]]), the pairwise homographies can be operated to recover whole areas. | Thus, taking benefits of the network structure of the data (descibed [[#Network_structure| below]]), the pairwise homographies can be operated to recover whole areas. | ||
This procedure is done by building a new graph centered on a selected node, and linked to every node that was connected to it in the original network (without notion of directionality). All other nodes are only connected (as targets) to this central node. | This procedure is done by building a new graph centered on a selected node, and linked to every node that was connected to it in the original network (without notion of directionality). All other nodes are only connected (as targets) to this central node. | ||
Each one of the edges is characterised by an homography between the central node (anchor) and the connected component (target). These homographies are computed as the product of pair-wise homographies along the shortest path linking the selected central node to the target in the original graph (see [https://github.com/noe-d/AlignmentTool/blob/ | Each one of the edges is characterised by an homography between the central node (anchor) and the connected component (target). These homographies are computed as the product of pair-wise homographies along the shortest path linking the selected central node to the target in the original graph (see [https://github.com/noe-d/AlignmentTool/blob/086d8ccd21de3c4fad5645c505eb057b71825f91/cadastre_matching.py#L1001 <code>buildCenteredNetwork</code>]). | ||
The two images below show an example of cadastres composition, either using direct match (left) or homographies propagation along a path in the network (right). One can see that the quality of the composition is better in the direct match configuration, yet the propagation still provides satisfying results considering that it encompasses the proliferation of errors along four matches. | The two images below show an example of cadastres composition, either using direct match (left) or homographies propagation along a path in the network (right). One can see that the quality of the composition is better in the direct match configuration, yet the propagation still provides satisfying results considering that it encompasses the proliferation of errors along four matches. | ||
| Line 303: | Line 280: | ||
[[Image:matching_flowchart.png|x300px|thumb|right|Matching flowchart.]] | [[Image:matching_flowchart.png|x300px|thumb|right|Matching flowchart.]] | ||
==== | The AlignemntTool service is provided as a jupyter notebook<ref name="notebook">Kluyver, T., Ragan-Kelley, B., Fernando Pérez, Granger, B., Bussonnier, M., Frederic, J., Willing, C. (2016). Jupyter Notebooks – a publishing format for reproducible computational workflows. In F. Loizides & B. Schmidt (Eds.), Positioning and Power in Academic Publishing: Players, Agents and Agendas (pp. 87–90). User site: https://jupyter.org</ref>. It offers easily understandable ways to preprocess, match and recompose the cadastres, while requiring only low computational literacy. | ||
The different steps are described in the notebook to guide the user during its use. Few considerations about the functionalities of the tool and the way they are meant to be used are reported in this section. | |||
==== Preprocessing ==== | |||
AlignmentTool allows to preprocess the cadastres in two main ways. They can be reoriented using the bearing arrows potentially drawn on the cadastres, and renamed, which can be very convenient for further uses (eg. referring to them directly by their label during the matching process). Yet, in the context of this project the rescaling step was not included in the preprocessing pipeline. It could however be added with little efforts based on already developed functions. | |||
= | These modifications can then be saved. Plus, edges can be computed through Canny edge detection<ref name="canny">Canny, J. (1986). A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, (6), 679–698.</ref> in order to provide a coarse, but quick, denoising of the images. This can be used as a low-cost line detector. | ||
==== | ==== Matching ==== | ||
The matching process (illustrated on the matching flowchart on the right) takes the form of a constant dialog between the user and the machine. First the user needs to establish discussion by entering the labels of the anchor and target cadastres. Both of them will then be displayed in the notebook. The anchor will lie on the left-hand side. The user must draw the bounding-box around the template to be used for TM on this image. The target cadastre is then displayed on the right-hand side and the user can select the area within which the TM process should occur. This selected area should be large enough to include completely the template and all its rotated version). A boolean parameter also allows to disable the rotations of the templates if the cadastres have already been correctly oriented. The best match found through TM is then displayed as the composition of both of the cadastres. The user must evaluate this match and tell to the algorithm if the match is satisfying, thus should be stored, or if it has to be discarded. This is an iterative process meant to be realised until completion of the studied area. | |||
==== Visualisation ==== | |||
[ | The results can be visualised within the notebook, either by printing the structure of the graph built during the process or, more graphically, by displaying the composition of a pair or more cadastres. Note that if several representations of the cadastres are available (eg. scans, edges, detected lines, etc.) all of them can be used by adjusting one parameter. | ||
==== Saving and loading ==== | |||
Finally two functions provides handy ways to save/load the graphs obtained through the process in/from JSON format. The JSON as the architecture described [[#Network structure| above]]. | |||
=== Case Study: La Rochelle 1811 === | |||
La Rochelle fortifications' inner cadastres from 1811 have been selected to assess the usability and performances of the tool. | |||
In order to reduce the noise on the images, lines have been extracted from the cadastres (see [[#Lines_detection_process| here]]). These files have been renamed together with the initial cadastres (it took 1min30s from initialisation to saving), and TM has been performed on the predicted lines. Independently of the considered cadastres, 80 angles were tested, for each degree between -40 and 40. While this is quite computationally expensive, the computational time is mainly dominated by the display of the composition. | |||
As a benchmark, details of the process are detailed in the table below. "Attempts" refers to the number of attempts before obtaining a satisfying match, "Time" is the corresponding time. * The total time also includes the initialisation and the post-matching visualisation of the whole area process. | |||
{| class="wikitable" style="margin-left: auto; margin-right: auto; border: none;" | |||
|- | |||
| | |||
| | |||
| | |||
| | |||
| | |||
| | |||
| | |||
| | |||
! Total | |||
|- | |||
! Steps | |||
| A<sub>2</sub>→A<sub>1</sub> | |||
| B→A<sub>2</sub> | |||
| B→C | |||
| D→A<sub>1</sub> | |||
| E→D | |||
| C→F<sub>1</sub> | |||
| F<sub>1</sub>→F<sub>2</sub> | |||
! 7 | |||
|- | |||
! '''Attempts''' | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 2 | |||
| 1 | |||
| 1 | |||
| 1 | |||
! 8 | |||
|- | |||
! Time | |||
| 24" | |||
| 30" | |||
| 28" | |||
| 46" | |||
| 33" | |||
| 37" | |||
| 38" | |||
! 4'44" * | |||
|} | |||
Note however that these statistics were obtained thanks to previous knowledge of the cadastres. Few time was spent selecting adjacent cadastres or looking for overlapping areas. These figures might be much higher on first trials (in particular it would be really surprising to have such low number of attempts on a first investigation, resulting ultimately in more time spent). | |||
The results from this process are exhibited below as the realignment of the eight considered cadastres (A<sub>1</sub> was taken as the central node for reconstruction). From a human perspective, the results obtained are mostly satisfying even thought there seems to be some incoherences around ''le havre'' and the ''quartier du Perrot'' (see [https://fr.geneawiki.com/images/2/28/17300_-_La_Rochelle_-_Enceinte_Ferry_1.jpg here]) in the bottom middle. Nonetheless this is also due to the quality of the cadastres that seem to disclose inconsistencies in scales around this neighbourhood. | |||
[[Image:LaRochellePoC_result_reduced.png|x600px|thumb|center|Alignment of La Rochelle's 1811 Napoleonic cadastres.]] | |||
These results can be reproduced by downloading the data folder <code>LaRochelle_PoC</code> from the shared [https://drive.google.com/drive/u/0/folders/0AKml0aowcS4wUk9PVA Google Drive] and putting it at the same root as the AlignmentTool repository. | |||
Then the network can be loaded, using the function presented in the last section of the notebook, and the map recomposed. Matches can also be recomputed in the section '''Matching''' of the notebook. | |||
== Lines detection process == | == Lines detection process == | ||
When time to reattach the napoleonian cadasters arrived, the only data available were the digitised maps themselves, but no process such as lines or class detection had been done on them. As mentioned previously, our method uses the lines detection files to find homologous points. It was therefore needed to process the cadasters we wanted to reattach. This task was done thanks to pretrained models provided by the teaching assistants, models trained on four cadasters (Neuchâtel, Berney and Melotte from Lausanne and finally Venice). | |||
=== dhSegment === | |||
[https://github.com/dhlab-epfl/dhSegment '''dhSegment''']<ref name="dhSegment">Ares Oliveira, S., Seguin, B., Kaplan, F. (2018). ''dhSegment: A generic deep-learning approach for document segmentation''. GitHub Repository: https://github.com/dhlab-epfl/dhSegment</ref> presents itself as a tool for Historical Document Processing. It can be used to recognise several types of elements in different digitised document types. It is based on a CNN-architecture. | |||
=== Procedure === | |||
The first step was to slice each map in many parts. Indeed, because of their size, the algorithm was not able to process them all at once. Therefore, the maps were cut in 3x3 parts to reduce the computational cost (some of the maps even needed to be cut in 4x4). Each of these slices was then inserted in the whole lines detection pipeline. Finally, the slices were reattached together (a much simpler task than reattaching different maps, as long as the slicing method was kept in memory and it was only needed to invert it). | |||
== | === Limitations and possible improvements === | ||
As long as this step was one of the last that had been implemented, it can only be considered as a first draft and a few improvements could have been made on it if more time had been available. | |||
First, to make this first draft simpler, no overlap has been left between the slices of a map. As many tools of that type, '''dhSegment''' is known to have results of lower quality on the edge of the image. Adding an overlap between the slices could improve the sharpness of the line in junctions of the slices, even if no clear black line, or other problem of that type, can be seen on the actual obtained images. | |||
The second possible upgrade of this method could be source of much greater enhancement than the first one. The problem we want to mention here is the fact that the maps have not been pre-processed in order to remove all the non-map parts of the picture. The parts that could be removed in this step are text, map number or letter, compass rose, borders of paper, or all the white areas that were obviously crumpled by time and are now just source of noise for our pipeline. However, this is a purely manual work that could only be done with human selection on a software like Photoshop or GIMP. For that reason, it would unfortunately take way too much time to be performed in the context of this project. | |||
== Future Work == | == Future Work == | ||
In the future, we would like to improve the AlignmentTool: its functionalities, for example integrating rescaling and scale-invariant matching and other homologous points retrieval methods, as well as its UI/UX to make it more user-friendly and less austere. | |||
The alignment reconstruction method should also be revisited in order to encompass the matches of every adjacent cadastres and possibly distort the representation accordingly. The images composition could also be boosted using other techniques such as bundle adjustment<ref name="bundle">Brown, M., & Lowe, D. G. (2007). Automatic panoramic image stitching using invariant features. International journal of computer vision, 74(1), 59-73. doi:[https://doi.org/10.1007/s11263-006-0002-3 10.1007/s11263-006-0002-3]</ref>. Once the foundation of the map of large areas recovered, an algorithm enabling slight variations of individual cadastres could be implemented in order to iteratively correct the whole structure. | |||
This tool could also be used to build ground truth datasets to investigate Machine Learning or Deep Learning approaches. | |||
It could also serve as a way for the machine to learn a metric of goodness of match by integrating the feedbacks from the users for both satisfying and discarded matches. | |||
The automation should also be reconsidered by integrating more domain knowledge and heuristic considerations into traditional Machine Learning and Computer Vision approaches. Nonetheless, in order to meet the challenges of this task state-of-the-art Deep Learning methods would certainly need to be embraced. | |||
Exploration of such techniques have already shown solid results on similar tasks<ref name="sun2021">Sun, K., Hu, Y., Song, J., & Zhu, Y. (2021). Aligning geographic entities from historical maps for building knowledge graphs. International Journal of Geographical Information Science, 35(10), 2078-2107. doi:[https://doi.org/10.1080/13658816.2020.1845702 10.1080/13658816.2020.1845702]</ref> <ref name="duan2017"> | |||
Duan, W., Chiang, Y.Y., Knoblock, C., Jain, V., Feldman, D., Uhl, J., & Leyk, S. (2017). Automatic Alignment of Geographic Features in Contemporary Vector Data and Historical Maps. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery (pp. 45–54). Association for Computing Machinery. doi:[https://doi.org/10.1145/3149808.3149816 10.1145/3149808.3149816]</ref>. | |||
Duan, W., Chiang, Y.Y., Knoblock, C., Jain, V., Feldman, D., Uhl, J., & Leyk, S. (2017). Automatic Alignment of Geographic Features in Contemporary Vector Data and Historical Maps. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery (pp. 45–54). Association for Computing Machinery. doi:[https://doi.org/10.1145/3149808.3149816 10.1145/3149808.3149816]</ref> | |||
Finally, to ease further analyses, or even improve the alignment scheme, the cadastres should be georeferenced and diachronically aligned with contemporary maps (for instance present-day [https://cadastre.data.gouv.fr cadastres] or [https://www.openstreetmap.org OpenStreetMap]). | |||
== References == | == References == | ||
Latest revision as of 14:09, 4 January 2022
Introduction
About a thousand of French napoleonian cadasters have been scanned and need from now to be aligned. A lot of different cities are included in this catalogue as La Rochelle, Bordeaux, Lyon, Lille, Le Havre and also cities that are no longer under French juridiction as Rotterdam.
Similarly to the work that had been done by the Venice Time Machine project, the idea is to attach every maps from a cadaster in order to get a single map of each city.
The main challenge for this project is the automatisation of this process, despite all inconsistencies in the maps, in terms of scale, orientation or conventions. Indeed, even if the instructions for the realisation of the maps were quite strict, some differences might last. For example, if there were nothing to show in some areas, geometers were allowed to represent them at larger scale. Other example, maps are not always oriented top-north (which is even not always indicated).
Deliverables
This project provides an exploration of possible automation leads to align cadastres, as well as the development of an interface (in the form of a Jupyter Notebook) to supervise this task.
Together with this report, the deliverables are:
- AlignmentTool: the tool developed to supervise cadastres' alignment. GitHub repository: https://github.com/noe-d/AlignmentTool.
- La Rochelle's 1811 cadastres case study (hosted on the shared Google Drive):
- predicted lines in La Rochelle's 1811 cadastres.
- graph storing the matches between adjacent cadastres in JSON format.
- recomposed image of La Rochelle's intramural cadastres.
Project setup
Methods exploration on Berney's cadaster
For the primary research of methods to reattach cadastral maps, the so called cadastre Berney from Lausanne (1827) has been used, as long as the ground truth for this particular case is known and lot of processing steps (as lines and classes predictions) have already been made. The first exercise has been made on the two first maps, using the lines prediction files. The quandary was to be able to detect the common parts of these two maps, in this case the Rue Pépinet and the top of Rue du petit chêne. Many different methods have been tested for that task, mainly with help of the OpenCV[1] python library. The researches have focused on scale invariant feature transform (SIFT), General Hough Transform (GHT)[2] and Template Matching (TM). The method that gave the most satisfying results (in terms of final output and computation time) was the template matching.
Template matching principle
Template matching is an OpenCV[1] function provided under the name cv.matchTemplate(). It takes as an imput a large scale image and smaller one, called template, that it will try to find in the first image. Concretely, the function slides the template through the initial image and for each position, gives a score of closeness. Note that the template always fully overlap the image, therefore the template must be fully included in the initial image. The function gives then as an output a matrix (an example of such a heatmap can be seen below) with score for each position. It is then easy to find the position of the best score.
The function provides several ways to compute that score. The one used for this project is the so called TM_CCOEFF_NORMED, defined as :

where

and where T and I refer to pixels of the template, respectively initial, images, and finally w and h are width, respectively height, of the template.
Template matching is known to have better results on simpler images exhibiting clear contrasts between shapes[3]. It is therefore a wise decision to preprocess the cadastres in order to bring their main features out. Thus, TM is performed here on the detected lines (see lines detection section for more details) when available, or on cadastres' edges otherwise.
First reattachment of two cadastral maps
Now that a sufficiently satisfying function had been found, the first milestone of this project was the first reattachment of two cadastral maps. The strategy was to manually cut a template in one of the maps and find the best match in the other one. Attaching the two maps together is then an almost straightforeward task, as long as the lines prediction files are only black (0) or white (255) pixels, and the final result is just the sum of the two of them adapted with the best matching position.
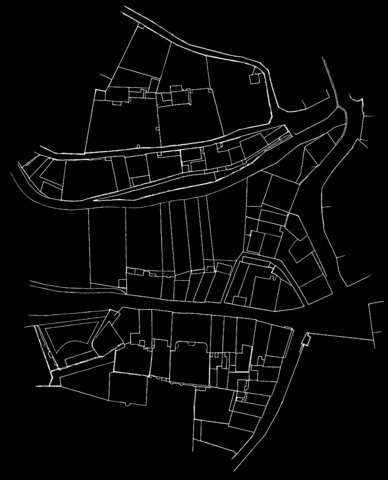
Berney 001

Template manually selected from Berney 001
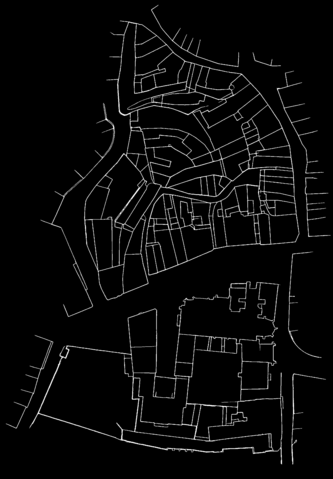
Berney 002





Organisation
As suggested before, the first steps of this project were quite empiric. Almost no step was automitzed and there were no other method than giving the two first maps to the function we were trying to use and hope that the result would be sufficiently satisfying and quickly computed. This finally gave us an heuristic argument to choose the template matching function.
But after this liminary choice, many challenges were still standing in front of us in order to perform large scale cadastres alignment.
- First, it was necessary to find criteria for the template’s extraction, ie. could we find a way that the pipeline detects by itself the common part of two maps ?
- Secondly, the orientation and scale differences in-between the maps were still problematic. Again, shall we indicate those variation « by hand » or could the pipeline understand it by itself ?
- A third problem was the capacity of our pipeline to be sufficiently precise to close loops of maps correctly, ie. would errors in successive matching cancel each other or propagate such that it would be impossible to place correctly the last map of a loop ?
- Finally, the probably most prominent challenge was our lack of metric. Indeed, the appreciation of the quality of the result of the matching was left to our own vision of the result. It would have been really beneficial to find an objective way to define the quality of the result, thanks to a metric.
The following table summaries the different ways we tried to handle those difficulties. Obviously, some methods were abandoned and some have been used until the end.
| Paradigm | Matching method | Template extraction | Data structure | Growth | Lines detection | |
|---|---|---|---|---|---|---|
| Week 4 | Automation | SIFT | - | - | 1 to 1 | - |
| Week 5 | SIFT and GHT | Manual | ||||
| Week 6 | GHT and TM | Semi-automated 1 to 1 | ||||
| Week 7 | ||||||
| Week 8 | Template Matching | Manual and automated along lines |
Dictionary | |||
| Week 9 | 1 to 1 or 1 to N adjacents | |||||
| Week 10 | ||||||
| Week 11 | Supervision | Manual with user tool | 1 to 1 1 to N recomposition |
First attempts on La Rochelle | ||
| Week 12 | Network | |||||
| Week 13 | Final steps on La Rochelle, with Google Colab and sliced images | |||||
| Week 14 |
Automation process


In order to automate the alignment task, efforts where put in three of the main challenges identified. A pipeline was then built to automatically extract templates, take into account variations in scales and orientations and iteratively spread over adjacent cadastres to cover large areas. However the incapacity to meet the fourth challenge, defining a semantically coherent metric, hindered the generalisation of this approach and led to mixed results.
This exploration was undertook on the lines pre-extracted from Berney's 1827 cadastres of Lausanne.
Automatic template extraction
In cadastres, the overlapping areas are situated on the borders of the maps. Hence, the template extraction process was automated to extract templates around most excentric points along given lines that still coded for a line.
To do so, an imaginary path parametrised by an angle is drawn from the center of the cadastre to its edge. Pixels values along this path are extracted and used to retrieve the coordinates of the last non-zero pixel value (ie. extracted line on the cadastre). A template can then be extracted around this point.
The function automating this task takes an integer N as argument that defines the number of templates to be extracted. Templates are then extracted along paths parametrised by the linear division of the circle in N pieces (see extract_templates). Examples are shown in the left hand side plot present in the figure on the right.
Nevertheless these plot mainly highlight the fragility of the matching method. Indeed they underline that the TM score doesn't align with the human understanding of the problem. Moreover, as TM is highly dependent on the templates, this approach is highly dependent on the chosen number of extracted templates N. For example here extracting 9 templates resulted in a coherent best match but extracting one less template yielded wrong results.
Orientation and scale integration
One of the factor deteriorating the quality of the matches are the slight variations of orientation. Thus, in order to limit this influence (and potentially to prepare to non-oriented cadastres) the matching process was made orientation invariant (over a given discrete range). The same procedure was applied to scales as Lausanne's cadastres relative scales are mixed between 1:1 and 1:2 (or inversly 1:0.5). The matching process was then a grid-search over the specified angles and scales, with scores obtained by matching the extracted template on the modified (rotated and rescaled) target cadastre.
However, beside increasing the computational cost, multiplying the number of parameters also heightens the chance of semantically incoherent match to get the best score (as there is only one, or few, good match and all others are deceiving).
NB.: at this state of the project, this method was achieved by rescaling and rotating the whole target cadastre. This approach is largely suboptimal and computationally very expensive, it was changed afterwards (as described here).
Peripheral growth
Both of the previously stated methods (Automatic template extraction and scale and orientation invariant TM) were then combined in an algorithm anchoring iteratively adjacents cadastres to the already integrated ones to spread the covered area. The list of adjacent cadastres were manually encoded and the parameters manually fine-tuned to reach meaningful results over several cadastres, see for example the left hand-side figure below. However this method demonstrated poor reliability and generalisation power, as illustrated on the right hand-side. There template 006 is wrongly matched on 008 and any additional consideration on this cadastre would be meaningless and detrimental to the general workflow.
- Iterative growth with successive anchors 001, 009, 010 and 008. Taking into account slight variations in orientation and two scales.

Before matching 006 onto 008. Matches are satisfying.

After matching 006 onto 008. Semantically wrong match.


Limitations
If automated, this approach still exhibited major drawbacks. First, it is computationally expensive. Plus, it is highly non-stable as it depends on the very sensitive TM algorithm. This matching method often produces semantically wrong results, which is even more true in less dense (or rural) areas. Moreover, poor matches cause dramatic error propagation. Finally, it is very time-consuming as it requires extensive manual fine-tuning of the parameters to reach meaningful results, even over reduced areas.
These issues inhibit any possibility of generalisation and complete automation. Nonetheless, most of these problems are believed to be, at least partly, solvable by determining a better metric to render the quality of the matches. A measure closer to human understanding could discard semantically wrong matches to avoid errors to plague the results. It would also ease the optimisation of the parameters, that could then be handled automatically through Machine Learning algorithms. Such metric could also take the form of an additional classifier based on more heuristics or directly be integrated by the machine through Deep Learning.
Facing the incapacity to define a convincing metric, we decided to shift paradigm and directly involve human understanding in the loop by developing a tool to supervise the alignment task.
AlignmentTool
The AlignmentTool was developed to offer a highly supervised method to perform the cadastres' alignment. The backend processes are mainly handled through OpenCv[1], the data structure is managed with NetworkX[4], and the Notebook interface relies on jupyter-innotater[5]. The architecture and proceeding of each of these components are detailed below. Finally, the results of the proof of concept undertook on La Rochelle's Napoleonic cadastres from 1811 within Ferry's rampart are described and illustrated.
Backbone
The development of this tool compelled us to slightly revise the conceptual and theoretical framework for the matching and composition processes. The three major steps consisting in homologous points retrieval, pair-wise transformations computation and propagation are described in this section.
Matching

The matching model aims at finding two pairs of homologous points in the anchor and target cadastres (see get_target_homologous). It relies on TM (described above). On the anchor cadastres the tagged positions are the top-left and bottom-right corners of the extracted template. On the target one, the corresponding points are retrieved from the best match found.
If both of the cadastres share the same orientation (ie. matches are evaluated without taking into account additional rotations), then the pixel associated with the top-left corner of the template corresponds to the location with the highest value computed through TM and the pixel associated with the bottom-right corner is given by adding the template width and height.
If both of the cadastres don't share the same orientation, this task requires slightly more efforts. This procedure iteratively rotates the template, resulting in images of different shapes filled with void, and performs TM using these rotated templates (see orientation_matching). Thus, the coordinates of the best match will correspond to the top-left corner of the best rotated template, which is no longer in line with the top-right corner of the extracted template. The new pixel coordinates corresponding to the orignial template top-left and bottom-right corners are retrieved by artificially rotating the original template and computing the displacement of specified points (see shift_template).
An example of points tracking in the rotated templates is shown on the figure on the right. The figure below displays the results obtained through this method on a pair of non-aligned cadastres.

Homography
Homographies are transformation matrices (3 by 3), widely used in computer vision, mapping points in one image to corresponding ones in another image. In the context of this project, homographies are restricted to Euclidean transformations (allowing rotations and translations but preserving the distance between every pair of points). However, as the rest of the implementation is more general, slight modifications of the homographies' computation could enable the intergration of more complex transformations (eg. affine or projective) within the pipeline.
The pairs of homologous points retrieved through the matching process allows to compute the corresponding homography between the anchor and target cadastres. On both images the pair of coordinates define a vector from the top right to the bottom left tags. As they are considered to refer to the same geographic entity, the cadastres can be re-oriented (relatively to one another) by calculating the angle α between these vectors. The translations in 𝑥 and 𝓎, t𝑥 and t𝓎, are computed by comparing points corresponding to the top left corner in the anchor image and target one (after re-orientation). The homography matrix is then given by:

This process is encoded in the function vector_alignment. It allows to turn the matches characterised by two pairs of homologous points into a transformation matrix, which can be applied on the target cadastre to obtain its composition with its anchor through warpTwoImages based on cv2.warpPerspective.
Propagation
Homographies demonstrate convenient properties that allow to propagate pairwise homographies in order to reconstruct larger areas.
- Inversion — If H1,2 is known, then H2,1 is given by the inverse of H1,2
Allows to get rid of the directionality of the graph - Composition — If H1,2 and H2,3 are known, then H1,3 is given by the product of H1,2 and H2,3
Allows to directly link each connected nodes to each others
Thus, taking benefits of the network structure of the data (descibed below), the pairwise homographies can be operated to recover whole areas.
This procedure is done by building a new graph centered on a selected node, and linked to every node that was connected to it in the original network (without notion of directionality). All other nodes are only connected (as targets) to this central node.
Each one of the edges is characterised by an homography between the central node (anchor) and the connected component (target). These homographies are computed as the product of pair-wise homographies along the shortest path linking the selected central node to the target in the original graph (see buildCenteredNetwork).
The two images below show an example of cadastres composition, either using direct match (left) or homographies propagation along a path in the network (right). One can see that the quality of the composition is better in the direct match configuration, yet the propagation still provides satisfying results considering that it encompasses the proliferation of errors along four matches.
- Alignment of cadastres with direct edge or through propagation.
Direct match from A1 to D.

Propagation of matches A1 to A2 to B to C to D.


Network structure
The matches (when selected by the user) are collected in a directed graph. The nodes are the cadastres (or their labels) and the edges link the anchors (cadastres within which templates have been extracted) to their targets (cadastres matched). The edges store information about the matches between anchors and targets: their score and informations related to the matched positions (top left and bottom right corners of the extracted template in the anchor and corresponding positions in the target). An exemple of a possible realisation of such graph (for La Rochelle, 1811) is shown below.
These graph can be saved in JSON format with the following generic structure:

{
"directed": true,
"multigraph": false,
"graph": {},
"nodes": [{
"h": int — height of the corresponding image,
"w": int — width of the corresponding image,
"label": str — name
}, {
"h": int — height of the corresponding image,
"w": int — width of the corresponding image,
"label": str — name
}],
"match": [{
"score": float — score of the template matching process,
"anchor_tl": tuple: two int — coordinate of the template top left corner on the anchor,
"anchor_br": tuple: two int — coordinate of the template bottom right corner on the anchor,
"target_tl": tuple: two int — coordinate corresponding to anchor_tl on target,
"target_br": tuple: two int — coordinate corresponding to anchor_br on target,
"anchor": str — name of the anchor cadastre\node,
"target": str — name of the target cadastre\node
}]
}
User guide

The AlignemntTool service is provided as a jupyter notebook[6]. It offers easily understandable ways to preprocess, match and recompose the cadastres, while requiring only low computational literacy.
The different steps are described in the notebook to guide the user during its use. Few considerations about the functionalities of the tool and the way they are meant to be used are reported in this section.
Preprocessing
AlignmentTool allows to preprocess the cadastres in two main ways. They can be reoriented using the bearing arrows potentially drawn on the cadastres, and renamed, which can be very convenient for further uses (eg. referring to them directly by their label during the matching process). Yet, in the context of this project the rescaling step was not included in the preprocessing pipeline. It could however be added with little efforts based on already developed functions.
These modifications can then be saved. Plus, edges can be computed through Canny edge detection[7] in order to provide a coarse, but quick, denoising of the images. This can be used as a low-cost line detector.
Matching
The matching process (illustrated on the matching flowchart on the right) takes the form of a constant dialog between the user and the machine. First the user needs to establish discussion by entering the labels of the anchor and target cadastres. Both of them will then be displayed in the notebook. The anchor will lie on the left-hand side. The user must draw the bounding-box around the template to be used for TM on this image. The target cadastre is then displayed on the right-hand side and the user can select the area within which the TM process should occur. This selected area should be large enough to include completely the template and all its rotated version). A boolean parameter also allows to disable the rotations of the templates if the cadastres have already been correctly oriented. The best match found through TM is then displayed as the composition of both of the cadastres. The user must evaluate this match and tell to the algorithm if the match is satisfying, thus should be stored, or if it has to be discarded. This is an iterative process meant to be realised until completion of the studied area.
Visualisation
The results can be visualised within the notebook, either by printing the structure of the graph built during the process or, more graphically, by displaying the composition of a pair or more cadastres. Note that if several representations of the cadastres are available (eg. scans, edges, detected lines, etc.) all of them can be used by adjusting one parameter.
Saving and loading
Finally two functions provides handy ways to save/load the graphs obtained through the process in/from JSON format. The JSON as the architecture described above.
Case Study: La Rochelle 1811
La Rochelle fortifications' inner cadastres from 1811 have been selected to assess the usability and performances of the tool. In order to reduce the noise on the images, lines have been extracted from the cadastres (see here). These files have been renamed together with the initial cadastres (it took 1min30s from initialisation to saving), and TM has been performed on the predicted lines. Independently of the considered cadastres, 80 angles were tested, for each degree between -40 and 40. While this is quite computationally expensive, the computational time is mainly dominated by the display of the composition.
As a benchmark, details of the process are detailed in the table below. "Attempts" refers to the number of attempts before obtaining a satisfying match, "Time" is the corresponding time. * The total time also includes the initialisation and the post-matching visualisation of the whole area process.
| Total | ||||||||
|---|---|---|---|---|---|---|---|---|
| Steps | A2→A1 | B→A2 | B→C | D→A1 | E→D | C→F1 | F1→F2 | 7 |
| Attempts | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 8 |
| Time | 24" | 30" | 28" | 46" | 33" | 37" | 38" | 4'44" * |
Note however that these statistics were obtained thanks to previous knowledge of the cadastres. Few time was spent selecting adjacent cadastres or looking for overlapping areas. These figures might be much higher on first trials (in particular it would be really surprising to have such low number of attempts on a first investigation, resulting ultimately in more time spent).
The results from this process are exhibited below as the realignment of the eight considered cadastres (A1 was taken as the central node for reconstruction). From a human perspective, the results obtained are mostly satisfying even thought there seems to be some incoherences around le havre and the quartier du Perrot (see here) in the bottom middle. Nonetheless this is also due to the quality of the cadastres that seem to disclose inconsistencies in scales around this neighbourhood.

{kind=link}
These results can be reproduced by downloading the data folder LaRochelle_PoC from the shared Google Drive and putting it at the same root as the AlignmentTool repository.
Then the network can be loaded, using the function presented in the last section of the notebook, and the map recomposed. Matches can also be recomputed in the section Matching of the notebook.
Lines detection process
When time to reattach the napoleonian cadasters arrived, the only data available were the digitised maps themselves, but no process such as lines or class detection had been done on them. As mentioned previously, our method uses the lines detection files to find homologous points. It was therefore needed to process the cadasters we wanted to reattach. This task was done thanks to pretrained models provided by the teaching assistants, models trained on four cadasters (Neuchâtel, Berney and Melotte from Lausanne and finally Venice).
dhSegment
dhSegment[8] presents itself as a tool for Historical Document Processing. It can be used to recognise several types of elements in different digitised document types. It is based on a CNN-architecture.
Procedure
The first step was to slice each map in many parts. Indeed, because of their size, the algorithm was not able to process them all at once. Therefore, the maps were cut in 3x3 parts to reduce the computational cost (some of the maps even needed to be cut in 4x4). Each of these slices was then inserted in the whole lines detection pipeline. Finally, the slices were reattached together (a much simpler task than reattaching different maps, as long as the slicing method was kept in memory and it was only needed to invert it).
Limitations and possible improvements
As long as this step was one of the last that had been implemented, it can only be considered as a first draft and a few improvements could have been made on it if more time had been available.
First, to make this first draft simpler, no overlap has been left between the slices of a map. As many tools of that type, dhSegment is known to have results of lower quality on the edge of the image. Adding an overlap between the slices could improve the sharpness of the line in junctions of the slices, even if no clear black line, or other problem of that type, can be seen on the actual obtained images.
The second possible upgrade of this method could be source of much greater enhancement than the first one. The problem we want to mention here is the fact that the maps have not been pre-processed in order to remove all the non-map parts of the picture. The parts that could be removed in this step are text, map number or letter, compass rose, borders of paper, or all the white areas that were obviously crumpled by time and are now just source of noise for our pipeline. However, this is a purely manual work that could only be done with human selection on a software like Photoshop or GIMP. For that reason, it would unfortunately take way too much time to be performed in the context of this project.
Future Work
In the future, we would like to improve the AlignmentTool: its functionalities, for example integrating rescaling and scale-invariant matching and other homologous points retrieval methods, as well as its UI/UX to make it more user-friendly and less austere. The alignment reconstruction method should also be revisited in order to encompass the matches of every adjacent cadastres and possibly distort the representation accordingly. The images composition could also be boosted using other techniques such as bundle adjustment[9]. Once the foundation of the map of large areas recovered, an algorithm enabling slight variations of individual cadastres could be implemented in order to iteratively correct the whole structure.
This tool could also be used to build ground truth datasets to investigate Machine Learning or Deep Learning approaches. It could also serve as a way for the machine to learn a metric of goodness of match by integrating the feedbacks from the users for both satisfying and discarded matches.
The automation should also be reconsidered by integrating more domain knowledge and heuristic considerations into traditional Machine Learning and Computer Vision approaches. Nonetheless, in order to meet the challenges of this task state-of-the-art Deep Learning methods would certainly need to be embraced. Exploration of such techniques have already shown solid results on similar tasks[10] [11].
Finally, to ease further analyses, or even improve the alignment scheme, the cadastres should be georeferenced and diachronically aligned with contemporary maps (for instance present-day cadastres or OpenStreetMap).
References
- ↑ 1.0 1.1 1.2 Bradski, G. (2000). The OpenCV Library. Dr. Dobb's Journal of Software Tools. User site: https://opencv.org
- ↑ Ballard, D. H. (1981). Generalizing the Hough transform to detect arbitrary shapes. In Pattern Recognition (Vol. 13, Issue 2, pp. 111–122). Elsevier BV. doi:10.1016/0031-3203(81)90009-1
- ↑ Hashimoto, M., Sumi, K., Sakaue, Y., & Kawato, S. (1992). High-speed template matching algorithm using information of contour points. In Systems and Computers in Japan (Vol. 23, Issue 9, pp. 78–87). Wiley. doi:https://doi.org/10.1002/scj.4690230908.
- ↑ Aric A. Hagberg, Daniel A. Schult, & Pieter J. Swart (2008). Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference (pp. 11 - 15). Documentation: https://networkx.org/documentation/stable
- ↑ Lester, D (danlester). (2021). jupyter-innotater. GitHub Repository: https://github.com/ideonate/jupyter-innotater.
- ↑ Kluyver, T., Ragan-Kelley, B., Fernando Pérez, Granger, B., Bussonnier, M., Frederic, J., Willing, C. (2016). Jupyter Notebooks – a publishing format for reproducible computational workflows. In F. Loizides & B. Schmidt (Eds.), Positioning and Power in Academic Publishing: Players, Agents and Agendas (pp. 87–90). User site: https://jupyter.org
- ↑ Canny, J. (1986). A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, (6), 679–698.
- ↑ Ares Oliveira, S., Seguin, B., Kaplan, F. (2018). dhSegment: A generic deep-learning approach for document segmentation. GitHub Repository: https://github.com/dhlab-epfl/dhSegment
- ↑ Brown, M., & Lowe, D. G. (2007). Automatic panoramic image stitching using invariant features. International journal of computer vision, 74(1), 59-73. doi:10.1007/s11263-006-0002-3
- ↑ Sun, K., Hu, Y., Song, J., & Zhu, Y. (2021). Aligning geographic entities from historical maps for building knowledge graphs. International Journal of Geographical Information Science, 35(10), 2078-2107. doi:10.1080/13658816.2020.1845702
- ↑ Duan, W., Chiang, Y.Y., Knoblock, C., Jain, V., Feldman, D., Uhl, J., & Leyk, S. (2017). Automatic Alignment of Geographic Features in Contemporary Vector Data and Historical Maps. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery (pp. 45–54). Association for Computing Machinery. doi:10.1145/3149808.3149816