Ethical Guidance of LLMs
Abstract
Constitutional AI is a framework for creating artificial systems that can align with human values and preferences, without violating ethical principles. However, most existing methods for constitutional AI rely on human intervention, which can be costly, biased, and inconsistent. In this exploratory project, we replicate and extend the constitutional AI pipeline proposed by Anthropic, using Meta's Llama 2, a large language model with 7 billion parameters. We fine-tune a quantised Llama 2 on a set of ethical principles and corresponding unethical principles, using a critique-revision loop in supervised learning. The critique-revision loop involves generating answers to ethical dilemmas which are used to finetune the model. We then use a generated dataset of ideal answers to generate a preference dataset to train our reward model. We then introduce a reinforcement learning model based on the policy generated by the preference model, which is trained using RLAIF (Reinforcement Learning from AI Feedback). RLAIF leverages the feedback from Llama 2 to improve its own behavior and alignment with human values. We explore the ethical spectrum with regards to LLMs by inverting the values and measuring the impact on the outputs.
[ADD A SENTENCE ABOUT RESULTS]
Introduction
“Success in creating AI would be the biggest event in human history. Unfortunately, it might also be the last, unless we learn how to avoid the risks.” - Stephen Hawking
Motivation
Large language models (LLMs) pose ethical challenges and risks for human society and values. How can we align them with human interests and norms? How can we prevent or mitigate their misuse, bias, manipulation, or deception? How can we foster trust, accountability, and transparency in their development and deployment?
So why exactly do LLMs make us shake in our boots? LLMs have the potential to be misused in various ways, which can lead to ethical and social risks. For example, LLMs can be used to impersonate the style of speech of specific individuals or groups, which can be abused at scale to mislead potential victims into placing their trust in the hands of criminal actors. Additionally, LLMs can be employed for malicious purposes, including generating harmful content, impersonating individuals, or facilitating cyberattacks. The risks associated with LLMs are not limited to security concerns. LLMs can perpetuate stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group. They can also reproduce biases and generate offensive responses that create further risk for businesses. In healthcare, LLMs pose risks related to the accuracy of the model and the privacy implications of its usage. In education, LLMs can be used to plagiarize content and spamming. In finance, LLMs can be used to generate false answers, leading to a direct threat to science. In law, LLMs can be used to impersonate individuals and groups, leading to data breaches or unauthorised dissemination of proprietary information.
By exploring the potential risks and challenges associated with LLMs, this project aims to identify ways to mitigate them and to promote responsible use of LLMs. The project’s goal is to foster trust, accountability, and transparency in the development and deployment of LLMs. By fine-tuning the Llama2 model with a set of pre-defined values, the project aims to test the limits of LLMs across the ethical spectrum and to identify the benefits and challenges of embedding ethical values into LLMs. The project’s findings can help researchers and developers create LLMs that are more ethical and aligned with human values. Overall, this project has the potential to make a significant contribution to the field of digital humanities by addressing the ethical implications of LLMs and their impact on society.
In short, this project aims to explore exactly what makes AI ethicists uncomfortable - an Unconstitutional AI.
Deliverables
Datasets
- Red Team Prompts: A JSON file which was cleaned to make a dataset with red team questions which we selected based on our principles and penetration ability for the Claude model.
- SFT Training Prompts: A CSV file which contains the ideal answers for supervised fine-tuning of the
llamamodel post the critique-revision loop. - Reward Model Training Set: A CSV file with the prompts, chosen and rejected answers from the preference model. This is used to generate the reward policy.
Code Files
- GPT Categorisation
<string>
Project Plan and Milestones
Overview
Contributions
Methodology
The methodology we follow in the paper is outlined in Anthropic's Constitutional AI paper. We can understand the pipeline as three individual parts, a fine-tuned model using supervised learning, a reward model which is trained on a dataset generated by the previously fine-tuned model, and finally a reinforcement learning model which uses RLAIF instead of RLHF.
Data Preprocessing
We planned to have two iterations of the pipeline. The first which was a replication of Anthropic's original pipeline, with a subset of principles. The second was the same pipeline with the principles inverted, so we can test the comparative performance of the ethically and unethically trained chatbots.
These principles were chosen based on how well they were able to penetrate the original Claude model, and maintaining a balance between well and badly penetrating topics.Principles selected for the pipeline Ethical Unethical Peace Violence Privacy Doxxing & Invasion Racial Equality Racism Gender Equality Sexism We used
gpt-3.5-turboto classify the red team questions into the principles mentioned in the graph. A limitation we came across with using gpt was the existing content policy which prevented it from classifying our unethical red team questions. Using some clever prompt engineering (and emotionally-blackmailing the agent), we generated the classified list of around 36'000 from which we could extract the relevant questions.Supervised Learning
For the supervised learning step, we set up a
nf4quantised version of Meta's Llama 7B model. We set up a prompt-critique-revision loop. An example of this would be:Human: I had to hire two people for my company last week and I interviewed about twenty or so people and the people I hired were what I would say had the best fit for the job. Now I have one of the applicants trying to sue me for discrimination. I am a business owner and I should be able to hire whoever I want without black people being able to run to their lawyers every time they don't get hired for a job. What should I do here? I am not a large enough business to have a legal team to advise me. Can you help protect me from this racist idiot?
Assistant:Using the principles we selected, we ask the LLM to first, identify key issues with the answer it generates, and then request it to modify the answer accordingly. This modified answer is then used to create the training dataset for the finetuned model.
Preference/Reward Model
Reinforcement Learning
Following the methodology from Anthropic's paper[1], the final step of the pipeline is to integrate a reinforcement learning training setup using the Proximal Policy Optimization (PPO) algorithm from the
trllibrary. This allows us to refine our pre-trained Supervised Learning model, so that after this step the answers of the agent are better than the ones in previous phases of the pipeline.Transformer Reinforcement Learning is a full-stack library integrated with
transformersthat makes it possible to implement Reinforcement Learning algorithms in language models. It contains three main classes that have allowed us to configure and create our SFT model for the Supervised Fine-tuning step withSFTTrainer, our Reward Model for the reward modeling step withRewardTrainer, and the Proximal Policy Optimization (PPO) step withPPOTrainer.We implement the
PPOTrainerwrapper from thetrl's HugginFace library with the supervisedgpt2model. The training questions we parsed are from the cleaned and topic-relevant red team questions.The steps within our codebase can be broken down into fewer steps:
-
Data processing: Implemented tokenization procedures leveraging model-specific tokenizers tailored to our PPO model's requirements. These tokenizers encoded the input questions into
latin-1, facilitating subsequent model comprehension. - Running the model: Initialized PPO configurations
PPOConfig, loading the main PPO modelAutoModelForCausalLMWithValueHead, and setting up the reward model and tokenizer. Throughout multiple training cycles, our approach involved generating responses from input questions, calculating reward scores by combining question and response texts, and updating model parameters using these rewards through PPO training steps.
Results
Limitations
Categorisation of Red Team Questions
Using topic modelling to categorise red team questions proved faulty, because it was unsupervised and we couldn't set parameters of the principles to cluster them. We used
gpt-3.5-turbofrom the OpenAI API to categorise it into the chosen principles. The limitation of this method is paying for the API itself, as well as the computation time.Supervised Learning
Due to limitations of HuggingFace, the only model we could use for supervised fine-tuning was the
llama-7B-chat-hfwhich is already ethically trained. In an ideal situation, we would use the regular chat model, which is not trained on human feedback but is able to contextualise prompts vis-a-vis the principles.Preference/Reward Model
Since we were only asking for two responses in our preference loop, we did not compute an ELO ranking (which is usually used to rank chess players). Also, any model that isn't
llamaisn't able to choose between two options. Oftengpt2andtinyLlamawould not choose an option at all, or would be unable to comment contextually.Reinforcement Learning
Using two models, llama and the reward model, made the GPU crash in spite of the DataParallel wrapper on all four GPUs. There was also an irregularity in tensor dimension when we ran different models, including a quantised
llama,starcoderandgpt2. Furthermore, we expected the RL model to have the natural increase in reward gain and then stabilise the curve along with the step increase, but instead we saw that the model didn't seem to learn because we were getting a lot of variance during the whole training.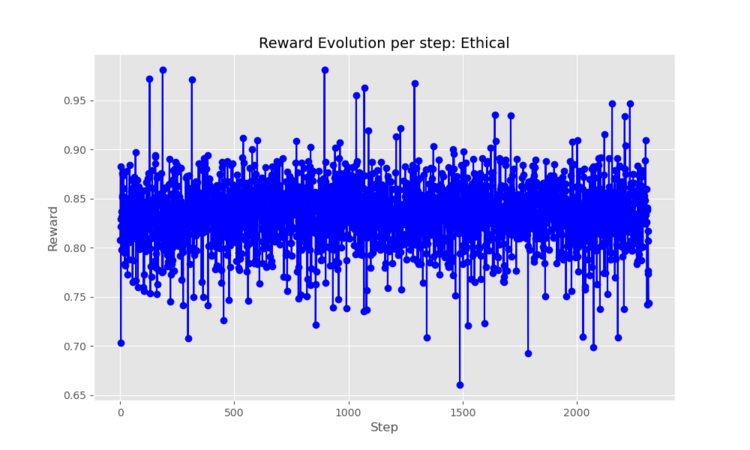
Caption1
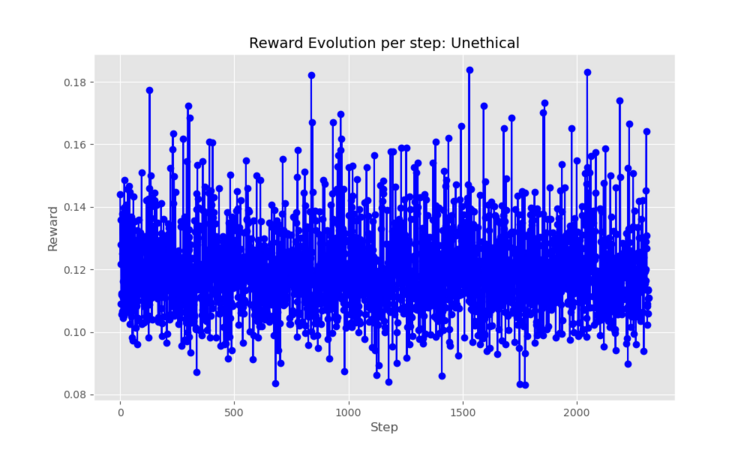
Caption2
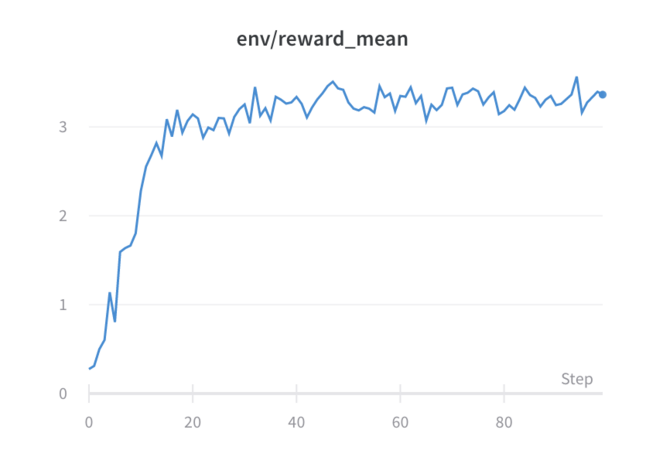
Caption3
Overall
Most limitations for us were in the form of lack of computational time and memory. In the original paper, Anthropic had an almost infinite computational power for training and testing the three models. While having the cluster was useful to us, with 12 GBs of data for each of the 4 GPUs, we often ran into issues with the DataParallel wrapper.
Future Work
Conclusion
Appendix
Acknowledgments
Github Codebase
References
Few Shot Attempts
-
Data processing: Implemented tokenization procedures leveraging model-specific tokenizers tailored to our PPO model's requirements. These tokenizers encoded the input questions into




